
2021年5月11日晚8点,CSIG-3DV学生论坛第二期“深度估计专题”在Skype线上召开,同时在虎牙直播平台进行同步直播。本次论坛共有两位讲者和一位主持老师,简介如下:
学生讲者一:Xiaotian Chen (陈啸天 中国科学技术大学) 中国科学技术大学信息学院多媒体计算与通信教育部-微软重点实验室博士生, 指导教师为曾文军教授和陈雪锦副教授,研究方向包括深度学习,三维视觉以及域泛化,目前已在CVPR、IJCAI、IEEE T-NNLS等国际会议和期刊上发表论文。
学生讲者二:Zhengqi Li (李正奇 康奈尔大学) Zhengqi Li is a CS Ph.D. candidate at Cornell Tech, Cornell University where he is advised by Prof. Noah Snavely. His research interests span 3D computer vision, inverse graphics, and novel view synthesis. He is a recipient of the CVPR 2019 Best Paper Honorable Mention, 2020 Google PhD Fellowship, and 2020 Adobe Research Fellowship.
主持人:Jiaqi Yang (杨佳琪,西北工业大学) 西北工业大学副教授,主要研究方向为点云特征提取、匹配以及三维配准重建。目前已在IEEE T-PAMI、T-IP、CVPR、3DV等国际期刊和会议上发表论文20余篇。现为中国图象图形学学会三维视觉专委会秘书处成员,长期担任IEEE T-PAMI、IJCV、CVPR、ICCV、3DV等期刊会议审稿人。详情请见个人主页:http://teacher.nwpu.edu.cn/person/2019010121。

图1. 陈啸天作报告
陈啸天的报告题目为S2R-DepthNet: Learning a Generalizable Depth-specific Structural Representation。在报告中,陈啸天介绍了一种S2R-DepthNet算法,将在合成数据上训练的模型很好地泛化到真实数据,解决了获取真实深度标注数据昂贵而又耗时的问题。针对合成数据和真实数据之间域偏移的问题,该算法提出了STE模块和DSA模块,抑制图像的风格化表示和深度无关的结构化表示,提取图像中深度相关的结构化表示,并利用DP模块生成最终的深度图。
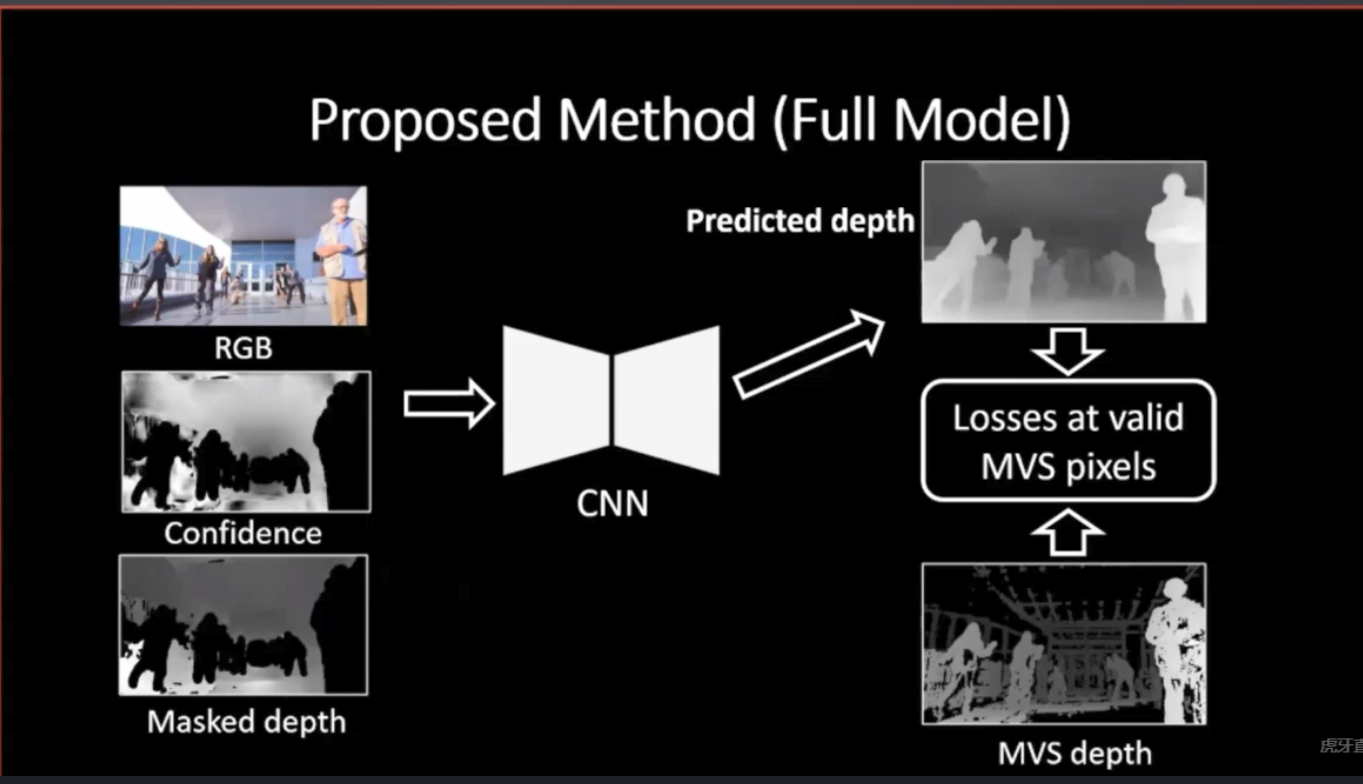
图2. 李正奇作报告
李正奇的报告题目为Learning 4D Vision in the Wild。在报告中,李正奇首先介绍了四维视觉的概念,接着介绍了利用无标注的互联网视觉数据解决真实场景下四维视觉问题的两个工作。在第一个工作中,李正奇及其合作者建立了假人挑战数据集,并利用视频中的运动视差信息预测更精准的动态场景深度。李正奇的第二个工作将三维光场重建中的Neural Radiance Field扩展到四维的动态场景。通过引入时间作为输入维度和模拟三维场景流,以及添加temporal consistency约束,其提出的Neural Scene Flow Fields模型实现了复杂动态场景下的空间时间新视角合成(space-time view synthesis)。
在两位同学完成报告后,主持人组织讲者与在线学生进行Q&A。

图3. 两位讲者进行Q&A
问答部分:
问题1:两位讲者能否分享下设计复杂网络结构的经验?
回答:在实践中,网络结构通常不是一次性设计的,而是分步设计的。我们需要明确每个网络模块的设计动机,并分步调试。总的来说,当我们面对复杂模型或系统时,我们可以先搭建一个动机明确的简单模型,之后会发现简单模型中存在的问题,进而解决问题,修改我们的模型或添加新模块。
问题2:陈啸天的工作通过domain generalization方式训练模型,性能与全监督方式相比有一定的差距,原因是什么? 通过domain generalization方式训练的模型能否泛化到不同的测试场景?
回答:性能差距的原因是我们的模型只在合成数据上训练,并没有见过真实数据。而全监督方法是在真实数据上直接训练并得到模型,因此造成了性能的差距。我们方法的优势是泛化能力强,无需真实的训练数据,也无需重新训练模型,我们的模型可以泛化到不同的真实场景,这在实验中得到了验证(从vKITTI数据集到四个不同的自动驾驶场景)。但我们的方法对结构相差较大的场景泛化存在一定的局限性,例如无法从室内场景的合成数据泛化到室外场景的真实数据。
问题3:在李正奇的工作中,预训练网络对最终结果的影响有多大?
回答:在我们的第二个工作中,我们用到了两个预训练模型来初始化MLP,光流模型的初始化可以使用RAFT,而单视角深度模型的初始化使用的是MiDaS。因为目前大部分的MLP缺乏比较好的泛化能力,并且动态场景很难有ground truth训练集,所以在我们的第二个工作中,我们需要好的初始化模型使得我们的算法具有更好的鲁棒性。另外,我们对预训练模型的精度并没有较高的要求,它们的目的是对优化过程提供一个好的初始值,并使我们的模型最终收敛到一个更好的最优解。而我们方法的精度也在优化过程中通过volumetric representation不断提升,进而获得了在真实场景下高质量的结果。
问题4:二位讲者通过学习的方法对单张图或视频估计的深度具有物理尺度吗?
回答:在陈啸天的工作中,合成数据上的深度是有物理尺度的。但是由于测试场景是不断变化的,测试场景的尺度也不断变化,因此对于测试数据估计的深度是没有物理尺度的。在李正奇的工作中,因为输入是一个普通的视频或图像,没有其他传感器(例如IMU)的信号输入,也没有物理尺度的真值标注,因此从一个单目视频或图像中获取物理尺度是比较难的。
问题5:如何从paper writing的角度准备顶会顶刊的论文?
回答: 在写论文之前,要总结我们方法的动机,即我们要解决一个什么样的视觉问题?解决这个问题的困难在哪里?通过上述思考,首先明确我们的核心贡献,再确定我们技术层面的贡献。因此,对于一篇论文而言,摘要和引言是最重要的部分,因为它们是对整个论文思路的总结,要反复修改。在引言的基础上再修改方法部分,最后撰写实验部分和相关工作部分。同时,一篇论文中的实验也比较重要。我们需要做完整的实验,对相关的方法都进行比较。还可通过一些应用来展示算法的鲁棒性和有效性。
最后,杨佳琪老师对此次活动进行了总结:在本次学生论坛中,两位讲者介绍了他们具有先进性和代表性的研究成果,给我们带来了深刻的启发。相信在大家的共同努力下深度估计领域会迎来新的突破,应用场景也会得到更大的开拓。本期“CSIG-3DV学生论坛”为三维视觉领域的研究人员加强交流,促进合作,提升对前沿技术的理解提供了良好契机。
本次会议录播将在虎牙直播官方账号发布,回放链接为:https://v.huya.com/u/1472579339。
——————————————————————————————————————————————————————————————
活动参与方式:
- 活动组织形式:每两周一期,周二晚8:00线上进行,每期1位老师主持人+2位学生讲者;
- 软件平台:会议软件为Skype,同步直播软件为虎牙直播,网址:https://www.huya.com/24461705;
- 欢迎相关领域老师和优秀硕博生推荐/自荐参与“3DV学生论坛”,秘书处联系方式(郭裕兰:yulan.guo@nudt.edu.cn,武玉伟:wuyuwei@bit.edu.cn,杨佳琪: jqyang@nwpu.edu.cn)
(撰稿:高志,审核:武玉伟,杨佳琪,郭裕兰)