
本文简要介绍SIGGRAPH Asia 2020论文“Scene Mover: Automatic Move Planning for Scene Arrangement by Deep Reinforcement Learning”的主要工作。该论文提出了一个实现场景转换的新问题,即给定一个室内场景的初始布局和目标布局,如何自动化生成一个物体搬运序列,以实现初始布局到目标布局的转换。论文采用蒙特卡洛树搜索(Monte-Carlo Tree Search,MCTS)的框架建模状态和动作之间的因果关系,迭代地生成家具搬运序列。在这个框架中,采用Q-Learning的强化学习方法训练了一个深度神经网络,以指导MCTS方法的搜索。实验表明,该论文提出的方法在生成数据集和真实数据集上取得了与人规划能力相当的性能。
1.研究动机
在日常生活中,人们经常会根据特定的需要对当前场景布局进行调整。例如为了举办活动,需要对场地重新布置,对居家布局进行调整,重新摆放商店货柜等。为了对场景进行重新布局,人们通常需要解决两个问题:1)设计一个符合需要的新布局;2)移动物体到对应的新位置以实现新布局。近年来,很多工作在第一个问题上进行了尝试,即场景布局的自动化生成。然而,自动生成一个物体搬运序列,实现从初始布局到目标布局的转换这一问题还尚未得到解决,这也是一个极富有挑战的任务。该问题的难点在于物体搬运序列的规划是一个长序列规划问题,长序列中的每一步决策都可能对后续的决策产生影响,并且在短期内很难观测到当前决策对未来决策的影响。对于重布局的物体搬运序列规划问题而言,有可能某一个物体的移动会阻碍其他物体到达目标布局中的位置,进而无法完成实现目标布局这一任务。
使用暴力搜索的方式来解决物体搬运序列规划这个问题是不可行的,即使搬运的动作是离散的,一个搬运序列的搜索空间都是随序列长度指数级增长的。假设场景中有10个物体,每个物体都有四种动作(上、下、左、右四个方向移动),如果序列的长度为10,那么这个决策将存在1040可能的序列。显然,直接进行暴力搜索是很难解决这一问题。采用基于规则的启发式搜索则可以在一定程度上缓解搜索空间随序列长度成指数级增长的问题,然而设计一个能够解决大多数情况的通用规则是非常困难的,并且由于决策与环境(场景布局)密切相关,当环境发生变化时,也需要重新调整或设计规则,很难实现自动化生成搬运序列这一目标。
本文提出了一个名为Scene Mover的方法,自动化生成物体搬运的序列,实现从一个场景布局到另外场景布局的自动转换。给定一个初始场景布局和一个目标场景布局,Scene Mover生成一个包含一系列动作的规划,每一个动作定义为一个(“物体”,“路径”)元组,其中“物体”是选择需要移动的物体,“路径”是该物体的运动路径。本文使用强化学习训练了一个深度神经网络建模从当前的布局状态和动作到累积奖励值的期望(又称为Q值)的映射。为了实现长序列的决策规划,本文采用了MCTS搜索的框架建模当前的状态动作与未来的状态之间的因果关系。
本文的方法主要包括两个阶段:在第一阶段,训练一个深度神经网络(Q-网络),为蒙特卡洛树搜索提供先验知识;在第二阶段,采用Q-网络嵌入的蒙特卡洛树迭代地生成动作,最终得到一个动作序列完成从初始场景到目标场景的转换。
本工作的贡献主要体现在如下三点:
1.提出了自动化实现从初始场景布局到目标布局的搬运序列生成的问题,该问题的解决为场景自动生成和场景实现之间搭建了桥梁。
2.提出了一个嵌入深度强化学习的蒙特卡洛树搜索方法解决物体搬运序列规划问题。
3.设计实验证实了算法的有效性,并应用于多种不同场景。

2.相关工作
2.1 室内场景生成
在室内场景自动生成这一方向上,学者们进行了广泛的探索和研究。早期的工作有采用数据驱动的方法训练贝叶斯网络实现城市布局生成[1],也有采用基于空间关系规则的方法生成室内场景,通过物体的出现先验和物体之间的位置关系构建优化目标,通过优化目标函数生成场景布局[2]。得益于深度学习的发展和大规模室内场景数据集的提出,近年来,一些相关工作采用了深度网络生成室内场景。Wang等人[3,4]利用深度卷积网络学习场景中物体摆放的先验,预测物体的种类和出现的位置。Ritchie等人[5] 采用卷积或图模型为基础的生成式模型直接建模室内场景分布,通过采样生成新的室内场景。
2.2 路径规划
路径规划是一个经典问题,也是本文需要解决的问题之一。它的相关算法广泛应用于机器人、驾驶和智能代理模拟等领域。路径规划的方法可以粗略地分为以下的几类:路线图法、单元分解法和人工势场法[6]。
本文在生成动作序列规划时,需要考虑全局的物体的运动策略(即物体运动的先后顺序以及运动目的)以及局部的单个物体的运动路径规划。对单个物体路径规划时,本文采用了A*启发式搜索算法。
2.3 重布局规划
重布局规划在机器人领域也有一些相关研究,其中大多数的工作都是聚焦在桌面的重布局。在机器人领域中,考虑到机器人对于动作规划的可实现性,在动作空间定义上,相较于抓握动作(例如抓、拿、取等动作),非抓握动作(通常是“推”一类的动作)因其简单便于操作成为了动作空间定义的首选[7,8,9]。
本文解决的问题场景与机器人领域解决的场景有很大的不同,室内场景相较于桌面更加复杂,物体种类和数量更多,物件的形状和大小变化多样,场景的静态障碍物(例如墙和柱子)数量更多,因此更具有挑战性,现有的机器人领域的算法很难解决这一问题。
3.方法描述
3.1 问题定义
给定初始布局![]() 和目标布局
和目标布局![]() ,本文目标是生成一个可行的动作序列
,本文目标是生成一个可行的动作序列![]() ,通过执行这个动作序列能够将
,通过执行这个动作序列能够将![]() 转变为
转变为![]() 。
。
动作![]() ,
,![]() 为动作空间,定义为一个(“物体”,“路径”)元组,其中“物体”表示被选中需要执行运动的物体编号,“路径”表示物体所需要运动的路径,用坐标和朝向角来表示。为了提高搜索的效率,本文定义了一组稀疏的元动作来缩短决策序列,每个物体的可行的动作被定义为以下的五种:
为动作空间,定义为一个(“物体”,“路径”)元组,其中“物体”表示被选中需要执行运动的物体编号,“路径”表示物体所需要运动的路径,用坐标和朝向角来表示。为了提高搜索的效率,本文定义了一组稀疏的元动作来缩短决策序列,每个物体的可行的动作被定义为以下的五种:![]() 至
至![]() 四种动作分别为沿上、下、左、右方向运动直至遇到障碍物,是从当前位置沿一条可行的路径移动到目标位置,本文采用了A*算法搜索这样一条可行路径。如果场景中存在n个物体,则每个时刻的动作空间共有n*5种动作可以选择。
四种动作分别为沿上、下、左、右方向运动直至遇到障碍物,是从当前位置沿一条可行的路径移动到目标位置,本文采用了A*算法搜索这样一条可行路径。如果场景中存在n个物体,则每个时刻的动作空间共有n*5种动作可以选择。
为了生成可行的动作序列![]() ,本文定义了如下的优化目标:
,本文定义了如下的优化目标:
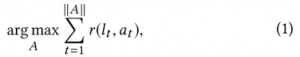
其中![]() 是一个奖励函数,表示在场景
是一个奖励函数,表示在场景![]() 下执行
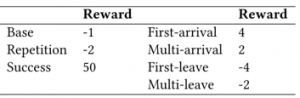
下执行![]() 所能获得的奖励值。奖励值的定义如下表所示,详细定义请参考论文原文:
所能获得的奖励值。奖励值的定义如下表所示,详细定义请参考论文原文:
在场景的表示上,本文采用了离散化的方格表示。将场景的俯视图离散化为N*N的方格中,并计算每个方格空间的占用情况,即是否有物体投影到当前方格以内,占用为1,未占用为0。
3.2 蒙特卡洛树搜索
本文采用了蒙特卡洛树搜索作为算法框架实现动作的长序列决策。搜索树中的每个节点代表一个场景状态,从父节点到子节点的有向边表示从父节点状态转移到子节点状态所执行的动作。在每个节点中存储了一系列的值,其中Q值用来表示从当前节点开始到未来依据某种策略所采取的动作能累积的奖励值的期望,N值用来表示该节点在搜索树中被访问的次数。边中存储了当前边经历的次数以及执行此边代表的动作所获得的即时奖励值。整个搜索树经过以下的四个步骤进行迭代式地生长和更新:
1)节点选择(selection)。搜索树从根节点开始,根据树搜索策略(Tree policy)不断向下搜索,直到选择了一个待扩展的边以及对应的待扩展节点。在这个过程中本文选取的树搜索策略是嵌入了策略网络的UCT,
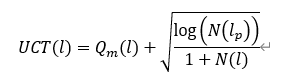
其中是使用神经网络预测的先验值。
2)节点拓展(expansion)。拓展1)中选中的边和节点。
3)模拟估计(simulation)。从2)中拓展的节点状态开始进行限制步数的模拟,将
模拟过程获得的累积奖励值作为这个节点的Q值估计。
4)回传更新(back propagation)。从新节点开始自下而上更新节点和边中存储的值。
搜索树的每次生长都会经过上述的四个步骤,当迭代次数达到预设次数时,会从根节点选择一个最优的动作作为当前时刻选择的动作。
3.3 Q-网络
为了强化MCTS在节点选择和模拟估计的能力,本文使用强化学习训练了一个网络来作为Q值的估计函数。Q网络的设计如下图所示:
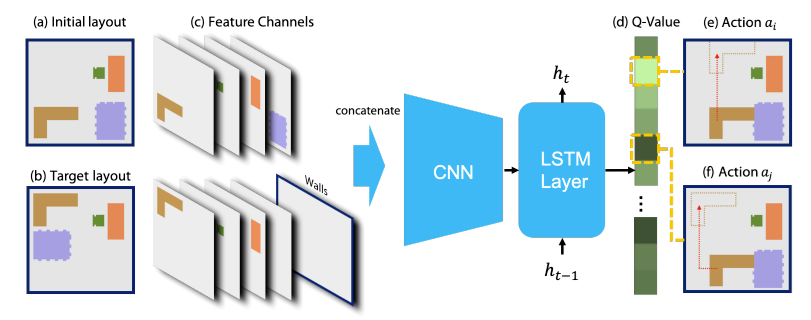
网络的输入包含了初始布局和目标布局的二维表示,经过深度卷积网络处理为特征向量,输入LSTM网络中,输出为一个Q值向量,表示每个对应动作的Q值。网络的训练需要最小化以下损失函数
![]()
![]()
其中![]() 是网络预测的布局
是网络预测的布局![]() 下执行动作
下执行动作![]() 的Q值,r是执行
的Q值,r是执行![]() 后获得的奖励值,γ是折扣因子
后获得的奖励值,γ是折扣因子
4.实验及应用
本文在生成数据集和真实数据集上分别开展了定量和定性实验,实验结果表明本文提出的方法与三种基准方法相比(用户实验、启发式方法、MCTS),具有更好的决策性能,其中,用户对比实验中,本文使用了所有受试者的表现性能的中值做为对比数据,本文的算法也超过了受试者在相同问题下的平均表现,达到了与人类决策平均水准相当的性能。
表2中展示了在不同的物体数量的实验条件下Scene Mover算法与其他算法完成的步数的竞赛比分结果(物体数量越大,决策难度越大)。表3展示了不同算法在不同物体数量的难度的数据上的成功率。实验结果表明,与三种基准方法相比,本文提出的方法表现出了更好的决策性能。


本文还展示了多个不同场景下的应用,例如图3所示是一个有多个楼层的场景,在搬运规划中,还考虑了相应的地形约束。更多应用示例细节,如将室外家具转移至空房间进行布置,请见论文原文。
5.结论
本文提出了在给定室内场景的初始布局和目标布局的前提下,如何将初始布局变成目标布局这一新问题,为解决这一问题,本文提出了一个嵌入深入强化学习的蒙特卡洛搜索树方法自动生成从初始布局到目标布局的搬运序列。本文采用了蒙特卡洛树搜索(Monte-Carlo Tree Search)的框架来建模状态和动作之间的因果联系并迭代式生成动作,在这个框架的基础上采用Q-网络的强化学习框架来训练一个深度神经网络指导树搜索算法进行搜索。在实验部分,本文验证了提出的算法能够在生成数据集和真实数据集上均取得很好的决策性能。本文在实验部分还展示了多种实际应用场景,为之后室内布局相关的自动化任务的探索提供了具有一定启发意义的思路。

6.参考文献
[1] Paul Merrell, Eric Schkufza, and Vladlen Koltun. Computer-generated Residential Building Layouts. ACM Transactions on Graphics, Vol. 29. 181,2010.
[2] Lap-Fai Yu, Sai Kit Yeung, Chi-Keung Tang, Demetri Terzopoulos, Tony F. Chan, and Stanley Osher. Make It Home: Automatic Optimization of Furniture Arrangement. ACM Transactions on Graph. 30, 4, 86, 2011.
[3] Kai Wang, Manolis Savva, Angel X Chang, and Daniel Ritchie. Deep Convolutional Priors for Indoor Scene Synthesis. ACM Transactions on Graphics 37, 4,70,2018.
[4] Kai Wang, Yuan Lin, Ben Weissmann, Manolis Savva, Angel X. Chang, and Daniel Ritchie. PlanIT: Planning and Instantiating Indoor Scenes with Relation Graph and Spatial Prior Networks. ACM Transactions on Graphics 38, 4, 2019.
[5] Daniel Ritchie, Kai Wang, and Yu-an Lin. 2019. Fast and Flexible Indoor Scene Synthesis via Deep Convolutional Generative Models. IEEE Conference on Computer Vision and Pattern Recognition, 2019.
[6] Alessandro Gasparetto, Paolo Boscariol, Albano Lanzutti, and Renato Vidoni. Path Planning and Trajectory Planning Algorithms: A general overview. In Motion and Operation Planning of Robotic Systems. Springer, 3–27, 2015.
[7] Haoran Song, Joshua A Haustein, Weihao Yuan, Kaiyu Hang, Michael Yu Wang, Danica Kragic, and Johannes A Stork. 2019. Multi-Object Rearrangement with Monte Carlo Tree Search: A Case Study on Planar Nonprehensile Sorting. arXiv:1912.07024, 2019.
[8] Weihao Yuan, Johannes A Stork, Danica Kragic, Michael Y Wang, and Kaiyu Hang. 2018. Rearrangement with Nonprehensile Manipulation Using Deep Reinforcement Learning. IEEE International Conference on Robotics and Automation, 2018.
[9] Changkyu Song and Abdeslam Boularias. Object Rearrangement with Nested Nonprehensile Manipulation Actions. arXiv:1905.07505, 2019.