
1.论文动机
许多计算机视觉任务,例如单目深度估计、遥感图像高度估计等,都有一个通用的基本目标,那就是对于给定单张图像,对图像上的每个像素都要预测一个连续的值。我们将这类问题统一定义为稠密的连续数值回归(Dense Continuous-Value Regression,DCR)任务。最近的基于深度卷积神经网络的方法显著改善了DCR任务的性能,尤其是像素级别的回归精度。但在复杂场景中仍然难以同时准确地恢复场景全局结构和精细的物体细节。本文受拉普拉斯金字塔对重建高质量信号的有效性启发,面向复杂场景下的多尺度结构表达,设计了拉普拉斯金字塔神经网络(LAPNet),包含一个拉普拉斯金字塔解码器用于场景结构重建和一个自适应的稠密特征融合模块去融合从输入图像中提取到的多尺度特征。具体的,我们构建了拉普拉斯金字塔解码器来有效地表达全局和局部场景结构。在我们的拉普拉斯金字塔解码器中,上层和低层分别表示场景的整体布局和物体局部细节,我们设计了一个残差细化模块去逐层级补充高频结构细节。为了恢复在金字塔的每一层结构,提出了自适应稠密融合模块,以自适应地融合多尺度图像特征。我们在三个重要的DCR任务中评估所提方法,分别是单目深度估计、单视角遥感图像高度估计以及人群计数任务。实验证明了在单目深度估计任务上,我们方法在NYUV2数据集以及KITTI数据集取得了定性和定量的最优性能,此外在遥感图像高度任务上的US3D数据集上和人群计数任务上也实现了最优的性能。这些结果证明了我们提出的LAPNet在多个任务上的通用性和有效性。
- 论文介绍
题目: [IEEE TNNLS 2020] Laplacian Pyramid Neural Network for Dense Continuous-Value Regression for Complex Scenes
作者顺序:陈雪锦,陈啸天,张翼腾,傅雪阳,查正军
(中国科学技术大学)
论文链接: https://ieeexplore.ieee.org/document/9286884
项目主页:http://staff.ustc.edu.cn/~xjchen99/Lapnet/tnnls.htm
代码链接:https://github.com/Xt-Chen/SARPN
- 创新点
(1) 针对单视角图像的稠密连续数值回归(DCR)任务提出了一个通用拉普拉斯金字塔网络LAPNet,设计了拉普拉斯金字塔解码器(LPD)来恢复复杂场景的多尺度结构,利用残差细化模块来有效整合相邻频段的信号。
(2) 为了更好的预测拉普拉斯金字塔解码器中不同频段的残差信号,设计了稠密特征融合模块来自适应地融合输入图像的多尺度特征。
(3) 所提LAPNet模型具有较强的通用性,可以被直接应用于各种不同的稠密数值回归任务,实验证明,我们的LAPNet在代表性的DCR任务(室内及室外场景单视角深度估计,遥感图像高度估计以及人群密度估计)中都取得了最优的性能,在视觉上可以恢复出复杂场景的精细结构。
- 相关工作
4.1 单视角深度估计
近期,利用深度卷积网络框架预测深度已经取得了不错的性能,这些方法大多利用更强大的网络架构,多尺度机制[1]或者条件随机场[2]来预测深度。但是由于网络学习能力以及平均回归损失函数的局限,在复杂场景下这些方法难以恢复出精细的场景结构。
4.2 遥感图像高度估计
早期的高度估计的方法一般通过几何推测来计算建筑物的高度。最近,Ghamisi 等人[3]首次尝试利用生成对抗网络来生成高度图,此外Zhang等人[4]利用多路融合网络生成了高分辨率的高度图,然而这些方法在目标场景复杂时常常产生不完整的建筑结构。
4.3 金字塔结构的深度神经网络
拉普拉斯金字塔首次被Burt等人[5]提出用于紧凑图像表达,之后Lai等人[6]提出深度拉普拉斯金字塔网络用于快速精确的图像超分辨,Fu等人[7]利用拉普拉斯金字塔将输入图像分解为多频带信号用于图像去雨,提升了深度神经网络对图像细节的表达能力。
- 方法描述
5.1拉普拉斯金字塔解码器
对于一张尺寸为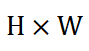 的图像
的图像![]() ,为构建一个
,为构建一个![]() 层的高斯金字塔
层的高斯金字塔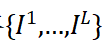 ,可通过一个下采样操作
,可通过一个下采样操作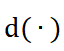 ,其中
,其中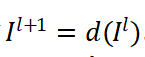 。具体的,利用低通滤波器进行2倍下采样可构造高斯金字塔。从一个高斯图像
。具体的,利用低通滤波器进行2倍下采样可构造高斯金字塔。从一个高斯图像![]() ,通过一个上采样操作
,通过一个上采样操作![]() 将其上采样到更高分辨率下,则需要一个残差信号
将其上采样到更高分辨率下,则需要一个残差信号![]() 来完全重建信号
来完全重建信号![]() 。基于高斯金字塔和每一层的残差,就可以构建一个拉普拉斯金字塔来完整恢复原始信号。在拉普拉斯金字塔的表达中,上层
。基于高斯金字塔和每一层的残差,就可以构建一个拉普拉斯金字塔来完整恢复原始信号。在拉普拉斯金字塔的表达中,上层![]() 是一个紧凑的低分辨率图像,每一层残差信号则是稀疏的。我们利用拉普拉斯金字塔的紧凑性和稀疏性,设计深度神经网络来恢复高分辨率二维信号。
是一个紧凑的低分辨率图像,每一层残差信号则是稀疏的。我们利用拉普拉斯金字塔的紧凑性和稀疏性,设计深度神经网络来恢复高分辨率二维信号。
对于一个具体的稠密数值回归任务,虽然之前的基于CNN的方法已经较大改善了平均像素估计精度,但对目标图像的场景结构尚不能很好地恢复,原因在于之前的方法利用复杂网络直接回归每个像素的值,但是忽略了场景目标间的结构关联。对比之下,拉普拉斯金字塔表达是通过逐步增加不同频带的信号,不同尺度的场景结构可以被逐层渐进式地恢复。因此,我们在预测端设计了拉普拉斯金字塔解码器,如图1所示。
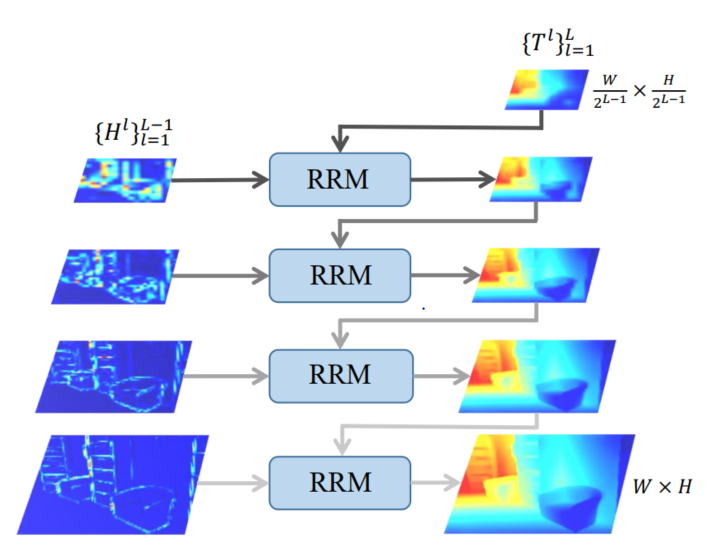
图1 拉普拉斯金字塔解码器结构图
我们首先用过一个CNN预测一个最低分辨率的目标图,然后我们逐步估计稀疏的残差![]() ,其中
,其中 ![]() 并且将这些残差加到从最低分辨率图像上采样的图像中。在金字塔的每一层,信号
并且将这些残差加到从最低分辨率图像上采样的图像中。在金字塔的每一层,信号![]() 。我们提出一个残差细化模块来代替简单的两部分加和,利用更多的低分辨率信号和残差信号的上下文信息,详细结构如图2所示。上一层的目标图
。我们提出一个残差细化模块来代替简单的两部分加和,利用更多的低分辨率信号和残差信号的上下文信息,详细结构如图2所示。上一层的目标图![]() 被上采样到当前层,加到当前层的残差图中,之后用一个残差模块用于进行细化。
被上采样到当前层,加到当前层的残差图中,之后用一个残差模块用于进行细化。
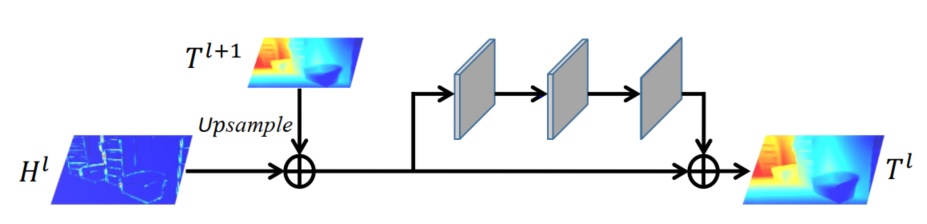
图2. 在第l层的残差细化模块
在拉普拉斯金字塔解码器中,较低分辨率的目标图包含了更低频的信息,主要用于描述全局场景布局,相反,更高分辨率的目标图包含更多高频信号,描述更多结构细节。通过逐级解码,场景的全局和局部结构都可以被很好地恢复。
5.2 自适应稠密的特征融合模块
为了在拉普拉斯金字塔解码器中恢复低频的目标信号![]() 和高频的残差
和高频的残差![]() ,我们设计了自适应稠密的特征融合模块,与以往由粗到细的特征融合不同,我们认为在所有尺度上的图像特征对于预测每个尺度的结构都是有利的,低频的特征也能有效地帮助预测高层的场景布局。因此,所提自适应稠密特征融合模块融合从RGB图像中提取到的所有尺度的特征来有效预测每一层的残差图,如图3(d)所示。此外我们还分析了我们的特征融合方法和其它特征融合方法(图3(a,b,c))的性能差异,进一步证明了该自适应特征融合模块的有效性。
,我们设计了自适应稠密的特征融合模块,与以往由粗到细的特征融合不同,我们认为在所有尺度上的图像特征对于预测每个尺度的结构都是有利的,低频的特征也能有效地帮助预测高层的场景布局。因此,所提自适应稠密特征融合模块融合从RGB图像中提取到的所有尺度的特征来有效预测每一层的残差图,如图3(d)所示。此外我们还分析了我们的特征融合方法和其它特征融合方法(图3(a,b,c))的性能差异,进一步证明了该自适应特征融合模块的有效性。

图3. 不同特征融合方法结构对比
5.3.整体框架
结合所提的拉普拉斯金字塔解码器和自适应稠密特征融合模块,我们的整体网络框架如图4所示,首先编码器提取出多尺度的图像特征,然后,多尺度特征图被送入自适应特征融合模块产生融合的特征金字塔。通过融合特征金字塔预测每一层的残差信号,之后拉普拉斯金字塔解码器以一种由粗到细的机制逐步预测多个目标图,最后一层就可以得到高分辨率的目标数值回归信号。
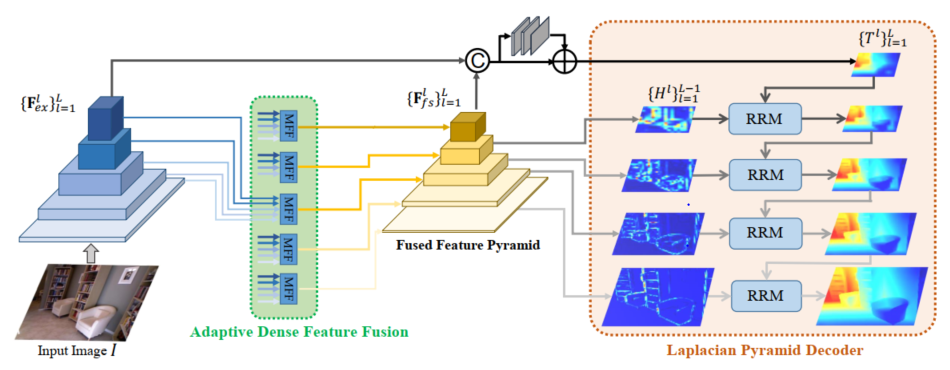
图4. 整体网络架构
- 实验结果
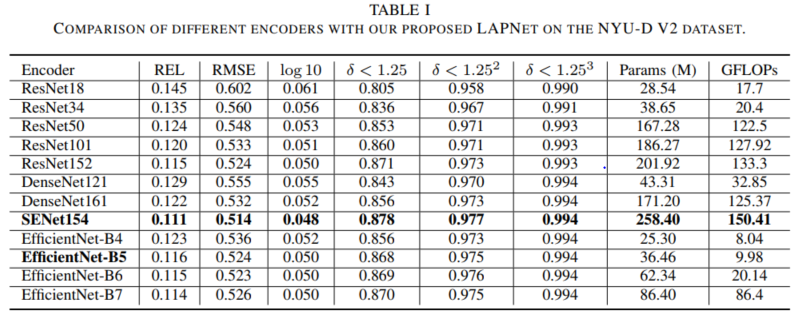
为了验证方法的有效性,我们在多个DCR任务上进行了评估,包括室内外场景的单目深度估计任务、单视角遥感图像高度估计以及人群密度估计任务。首先以单视角深度估计为例,我们对方法的每一部分的有效性做了分析,表I展示了我们的方法在不同基本骨架网络上的性能差异,可以看出方法在SENet154作为基本骨架网络时可以取得最好的性能,但其参数量过大。而使用Efficient-B5网络时,网络参数量大大降低,且仍具有较好的性能。
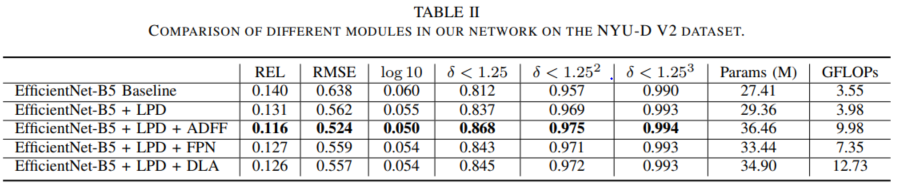
进一步我们分析了每一个模块的有效性以及不同特征融合模块的有效性,如表II所示,与其它特征融合方法相比,论文所提稠密特征融合模块表现出了更好的性能。
实验首先在单视角深度估计中公开的NYUD-V2数据集上进行了评估,可以看到我们的方法在定性和定量上都取得了最好性能,如表III所示以及图5所示。
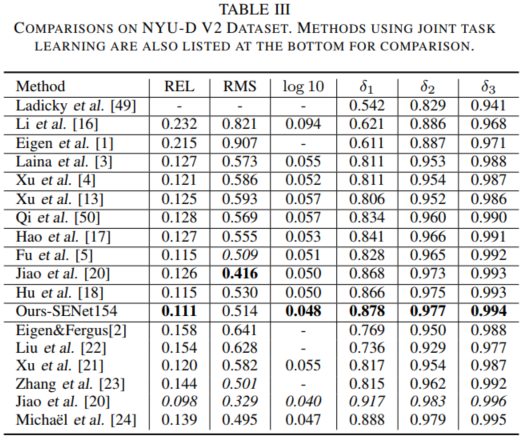
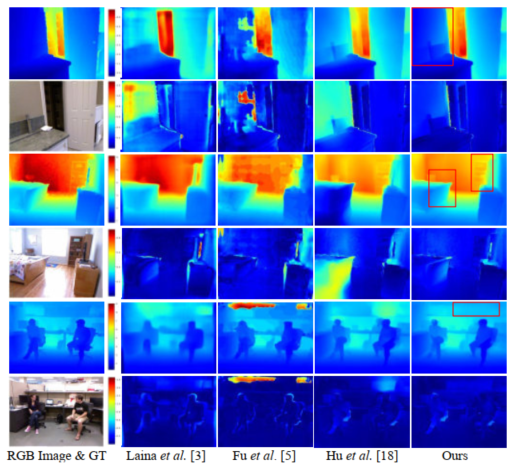
图5. 在NYUD-v2数据集上定性结果对比
除了室内场景,我们也评估了我们的方法在室外场景KITTI数据集的性能,如表IV和表V所示,我们的方法仍然取得了最好的性能,并在定性比较上也优于其它方法。


图6.KITTI数据集上的可视化结果对比
为了验证我们的方法在其它DCR任务上的有效性,我们对单视角遥感图像的高度估计任务做了评估,如表VI所示,在US3D数据集上,我们的方法也同样优于现有高度估计方法。图7则进行了定性对比,可以看出,我们的LAPNet可以准确恢复大尺度目标结构,同时获得精细目标的细节结构。
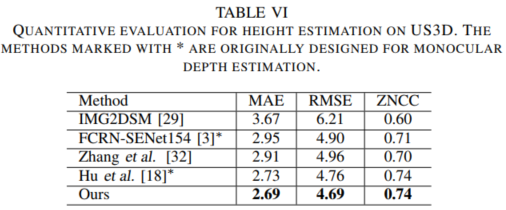
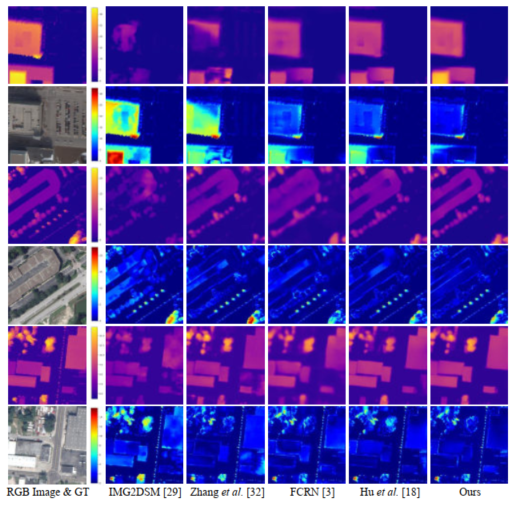
图7.遥感图像高度估计定性对比。
此外,我们也对人群密度估计任务做了性能评估,定量和定性比较分别在表VII和图8中,相较之下,我们方法仍然取得了优异的性能,充分验证了所提网络结构的通用性和有效性。
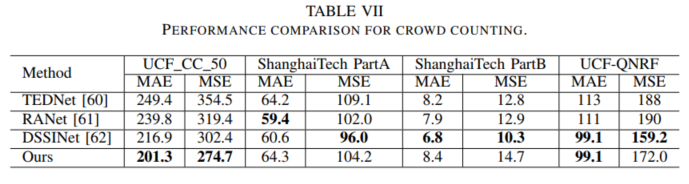

图8. 人群密度估计可视化比较
[参考文献]
[1] D. Eigen, C. Puhrsch, and R. Fergus, “Depth map prediction from a single image using a multi-scale deep network,” in Proc. NeurIPS, 2014, pp. 2366–2374.
[2] D. Xu, E. Ricci, W. Ouyang, X. Wang, and N. Sebe, “Multi-scale continuous CRFs as sequential deep networks for monocular depth estimation,” in Proc. IEEE Conf. Comput. Vis. Pattern Recognit. (CVPR), Jul. 2017, pp. 5354–5362.
[3] P. Ghamisi and N. Yokoya, “IMG2DSM: Height simulation from single imagery using conditional generative adversarial net,” IEEE Geosci. Remote Sens. Lett., vol. 15, no. 5, pp. 794–798, May 2018.
[4] P. Ghamisi and N. Yokoya, “IMG2DSM: Height simulation from single imagery using conditional generative adversarial net,” IEEE Geosci. Remote Sens. Lett., vol. 15, no. 5, pp. 794–798, May 2018.
[5] P. Burt and E. Adelson, “The Laplacian pyramid as a compact image code,” IEEE Trans. Commun., vol. COM-31, no. 4, pp. 532–540, Apr. 1983.
[6] W.-S. Lai, J.-B. Huang, N. Ahuja, and M.-H. Yang, “Fast and accurate image super-resolution with deep Laplacian pyramid networks,” IEEE Trans. Pattern Anal. Mach. Intell., vol. 41, no. 11, pp. 2599–2613, Nov. 2019.
[7] X. Fu, B. Liang, Y. Huang, X. Ding, and J. Paisley, “Lightweight pyramid networks for image deraining,” IEEE Trans. Neural Netw. Learn. Syst., vol. 31, no. 6, pp. 1794–1807, Jun. 20