
- 论文动机
生成动态场景的自由视角视频有很多应用,包括电影工业,体育直播和远程视频会议。近几年子弹时间的特效在春晚或一些综艺类节目开始越来越多的出现。现在效果最好的视角合成方法主要是NeRF[1]这个方向的论文,但他们有两个问题:(1) NeRF需要非常稠密视角来训练视角合成网络。比如NeRF论文中,一般用了100多个视角来训练网络。(2) NeRF只能处理静态场景。现在大部分视角合成工作是对于每个静态场景训一个网络,对于动态场景,上百帧需要训上百个网络,这成本很高。
- 论文题目
[CVPR 2021] Neural Body: Implicit Neural Representations with Structured Latent Codes for Novel View Synthesis of Dynamic Humans
彭思达(浙江大学),张远青(浙江大学),徐英豪(香港中文大学),王倩倩(康奈尔大学),帅青(浙江大学),鲍虎军(浙江大学),周晓巍(浙江大学)
代码开源: https://github.com/zju3dv/neuralbody
- 创新点
- 在稀疏视角下,单帧的信息不足以恢复正确的3D scene representation。论文的key idea是是通过整合时序信息来获得足够多的3D shape observation。大家平时应该能有这种感觉,观看一个动态的物体更能想象他的3维形状。我们论文用的就是这个intuition;
这里整合时序信息的实现用的是latent variable model。具体来说,我们定义了一组隐变量,从同一组隐变量中生成不同帧的场景,这样就把不同帧观察到的信息和一组隐变量关联在了一起。经过训练,我们就能把视频各个帧的信息整合到这组隐变量中,也就整合了时序信息。
- 相关工作
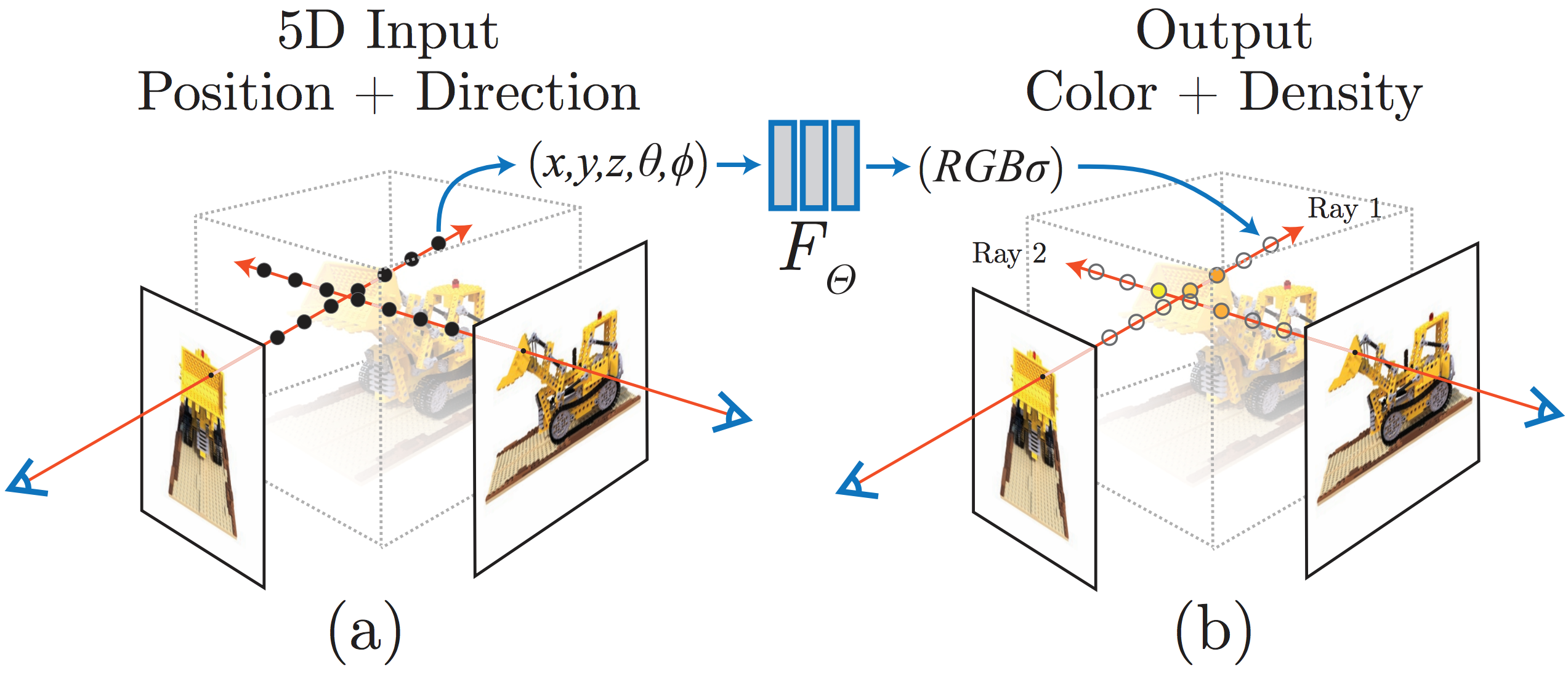
Neural radiance field (NeRF) [1]是ECCV 2020的论文,他用一个continuous volumetric representation来表示一个3维场景。对于一个场景的任意一点,NeRF取出3维坐标和视角方向,输入到一个MLP中,输出color和density。这个表示能通过volume rendering从图片中很好的优化场景的3D模型。这里的网络是一个global implicit function。global的意思是NeRF只用一个MLP网络去记录场景中所有3维点的颜色和几何信息。
- 方法描述
此部分可展开讲解。
5.1 Human motion capture
我们首先对输入的视频的每一帧预测一个人的粗糙的human mesh,比如SMPL模型。这里论文用了浙大三维视觉实验室开源的EasyMocap来检测每一帧的SMPL模型,代码地址为:https://github.com/zju3dv/EasyMocap

5.2 Structured latent codes
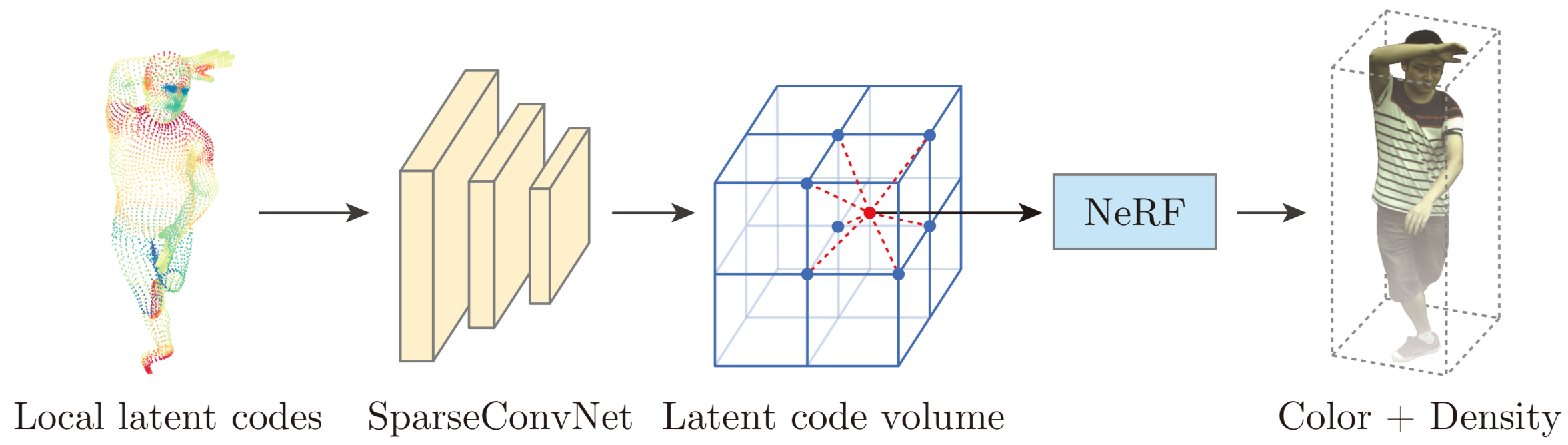
论文在SMPL模型上定义了一组离散的local latent codes。具体来说,就是在SMPL模型的网格节点上摆放latent codes。我们可以通过人体模型驱动structured latent codes的空间位置。

5.3 NeRF on structured latent codes
论文然后将NeRF改成一个local implicit function,也就是让NeRF从一组local latent codes中生成场景。具体来说,Neural Body将local latent codes输入到一个3维卷积神经网络,得到一个latent code volume,这样就能通过插值得到空间中的任意一点的latent code。然后Neural Body把latent code送入NeRF的网络中,就能得到相应的color和density。这里说NeRF是local implicit function的原因是,相比于原来NeRF用一个MLP记录整个场景的信息,这里场景的信息记录在local latent codes。比如脸部和手部的latent codes分别记录脸和手的appearance和shape information。
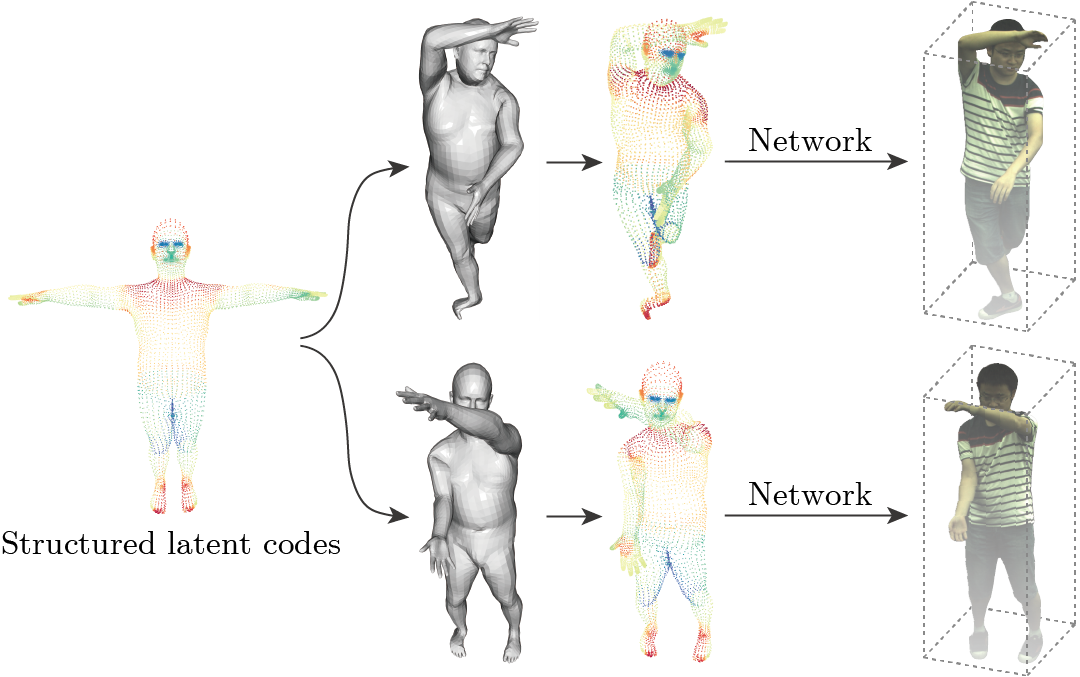
5.4 同一组structured latent codes生成不同帧的场景
对于不同的视频帧,Neural Body将latent codes摆放为对应的人体姿态,然后输入到NeRF中得到对应帧的3维场景。像NeRF一样,论文用volume rendering从图片中优化网络参数。通过在整段视频上训练,Neural Body实现了时序信息的整合。
- 实验结果
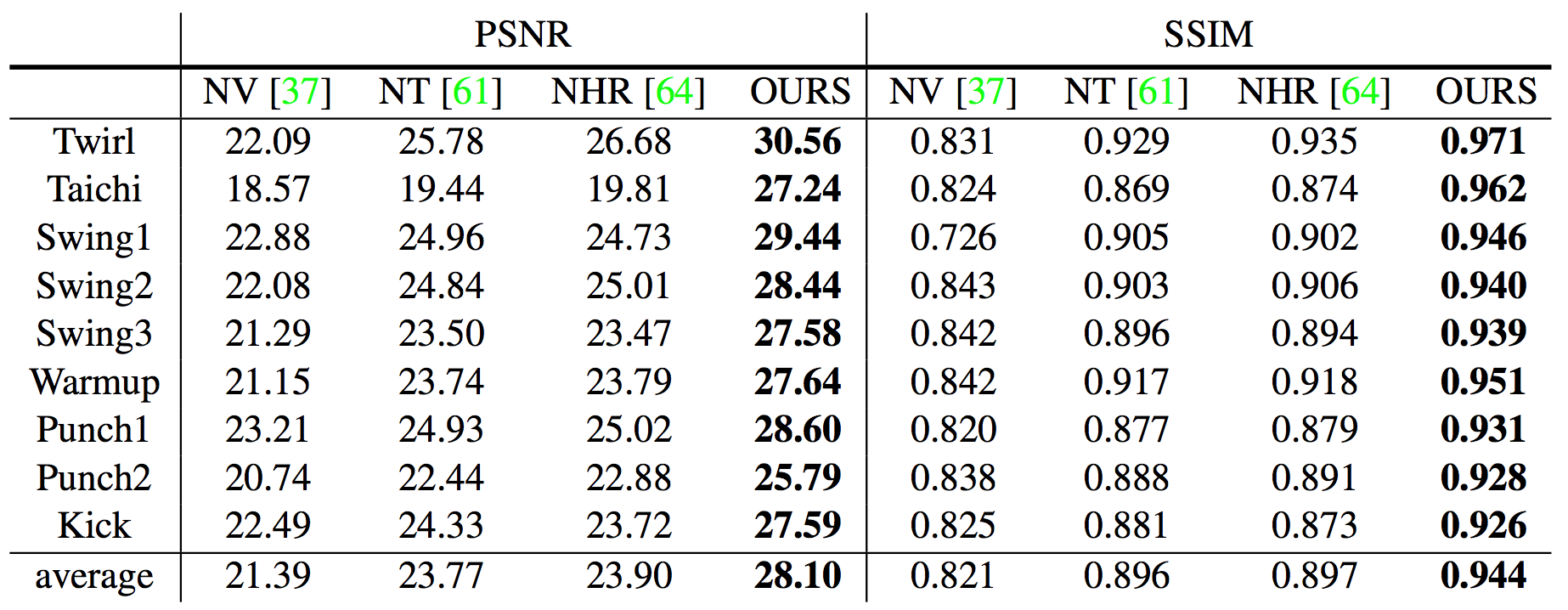
论文采集一个叫做ZJU-MoCap的多视角数据集,在上面和NeRF [1], Neural Volumes [2], Neural Textures [3], NHR [4] 比较。Neural Body在PSNR和SSIM指标上远远超过之前的方法。
- 参考文献
- [1] Mildenhall, Ben, et al. Nerf: Representing scenes as neural radiance fields for view synthesis. In ECCV, 2020.
- [2] Lombardi, Stephen, et al. Neural volumes: Learning dynamic renderable volumes from images. In SIGGRAPH, 2019.
- [3] Thies, Justus, et al. Deferred Neural Rendering: Image Synthesis using Neural Textures. In SIGGRAPH, 2019.
- [4] Wu, Minye, et al. “Multi-View Neural Human Rendering.” In CVPR, 2020.