
- 论文动机
6D姿态估计在场景三维定位、机器人3D无序抓取、虚拟现实和增强现实等领域有广泛应用。许多学者针对无序点云、RGB-D场景中的物体检测和位姿估计展开研究。早期工作主要集中在以特征描述子建立目标对象与场景实例之间的对应关系生成目标实例的位姿,但是这种方法的通用性和鲁棒性较差,难以满足对象表面特征分辨力低时的位姿估计需求。近期,涌现一些基于深度学习的位姿估计新方法,然而由于6D位姿估计训练数据标注难度大、硬件设备要求高和自监督深度学习算法预测精度低等原因限制了其在工业领域的应用。
针对以上问题,中国科学院自动化研究所联合苏州中科行智智能科技有限公司发表在TIP 2021上的论文,研究利用点对特征和模型中心之间的几何关系,提出基于中心点投票机制的6D位姿估计新方法,提高6D位姿估计方法的鲁棒性、计算效率和准确性。在3D工业点云场景中,其性能优于现有的方法。
- 论文题目
[TIP 2021] Efficient Center Voting for Object Detection and 6D Pose Estimation in 3D Point Cloud
郭建伟(中国科学院自动化研究所),邢学军(中国科学院大学),全卫泽(中国科学院自动化研究所),严冬明(中国科学院自动化研究所),顾庆毅(中国科学院自动化研究所),刘洋(苏州中科行智智能科技有限公司),张晓鹏(中国科学院自动化研究所)
论文链接: https://ieeexplore.ieee.org/document/9429889
- 创新点
- 提出基于点对特征(PPF)的复杂点云场景物体检测及6D位姿估计方法,相比传统的点云场景位姿估计方法更加高效、鲁棒;
- 为了更加准确地估计备选6D位姿,基于物体中心和点云点对特征之间的几何关系提出一种中心点投票策略;
- 基于中心点投票机制,提出一种新的备选位姿聚类和验证方法,同样,该方法也适用于点云场景中多物体和多实例对象的检测。
- 相关工作
一般来说,三维场景的目标检测和6D位姿估计主要有三个技术方向:模板匹配、特征描述子匹配和深度学习。
4.1 模板匹配方法
模板匹配方法将目标转化为一系列模板,然后在整个场景图片上搜索模板的位置,得到目标实例的位姿。该方法具有实时性强、易于实现等优点,得到许多学者关注,其中最著名的是LINEMOD,它主要解决复杂背景下三维物体实例的实时位姿估计问题。此外,Hodaň等人提出了一种多个无纹理刚性物体在RGB-D图像场景中检测和6D位姿估计方法,它在处理多个对象时,通过哈希表快速过滤和投票过程,获得了更高的匹配效率。这些方法的主要缺点是由于光线变化、物体表面纹理和场景遮挡等导致复杂场景中目标实例的检测和位姿估计性能下降。
4.2 特征描述子匹配方法
局部特征描述子的设计目标是建立目标对象与场景中目标实例的一一对应关系,具体先设计一种具有旋转平移不变性的特征表述子,确定目标对象与场景之间的相似对应点对,接下来根据相似对应点对估计出目标对象粗匹配位姿,最后利用迭代最近点算法(ICP)精确优化目标对象的匹配位姿。然而,这些方法的性能并不稳定,特别是目标包含平面和规则曲面时,效果较差,因为这些描述子在平面和规则曲面上的分辨能力较弱,关键点选取和匹配比较困难。
Drost等人提出了一种基于点对特征(PPF)和霍夫投票的3D场景目标检测和6D位姿估计框架,并在工业领域有广泛应用。许多研究者对该框架进行了改进,以提高估计精度和执行效率。虽然这些基于传统PPF的目标位姿估计方法已经取得了很好的效果,但是对场景参考点的选择、投票过程、及其后处理等具体细节还有很大提升空间。
4.3 深度学习方法
近年来,基于学习的目标检测和6D位姿估计成为研究热点。Sundermeyer等设计了一种基于RGB的实时增广自动编码框架,用于目标三维方位估计,该增广自动编码器通过对三维模型视图进行自监督训练,不需要任何真实的姿态标注数据。为了进一步提高在高遮挡场景中的表现,Wang等提出了一个端到端的深度学习框架,称为DenseFusion,将RGB值和点云以像素级别嵌入和融合,此外,他们使用ICP代替后处理,将其集成到框架中,以获较好的性能。然而,这些方法基于RGB/RGB-D场景,不能直接应用于无序三维点云场景中三维目标检测和6D位姿估计。
- 方法描述
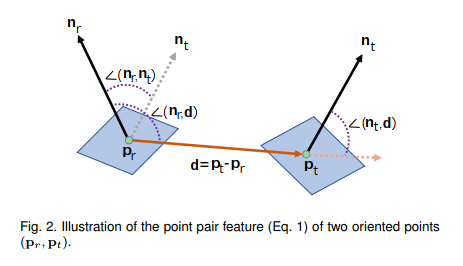
图1 点对特征(PPF)描述子示意图
本文拟采样的技术方案与传统的PPF霍夫投票算法类似,其点对特征(PPF)是一种全局特征描述子,它描述两点的位置和法向之间的相对关系。如图1所示,给定参考点![]() 和目标点
和目标点![]() 及其法向
及其法向![]() 和
和![]() ,点对特征(PPF)可用一个四维向量表示,定义为:
,点对特征(PPF)可用一个四维向量表示,定义为:
![]()
其中,d=![]() –
–![]() ,
,![]() 表示矢量a和b之间的夹角。
表示矢量a和b之间的夹角。
本文拟采样的技术方案主要分为点云预处理、目标对象离线建模、基于PPF中心投票估计备选位姿、备选位姿验证4个步骤。
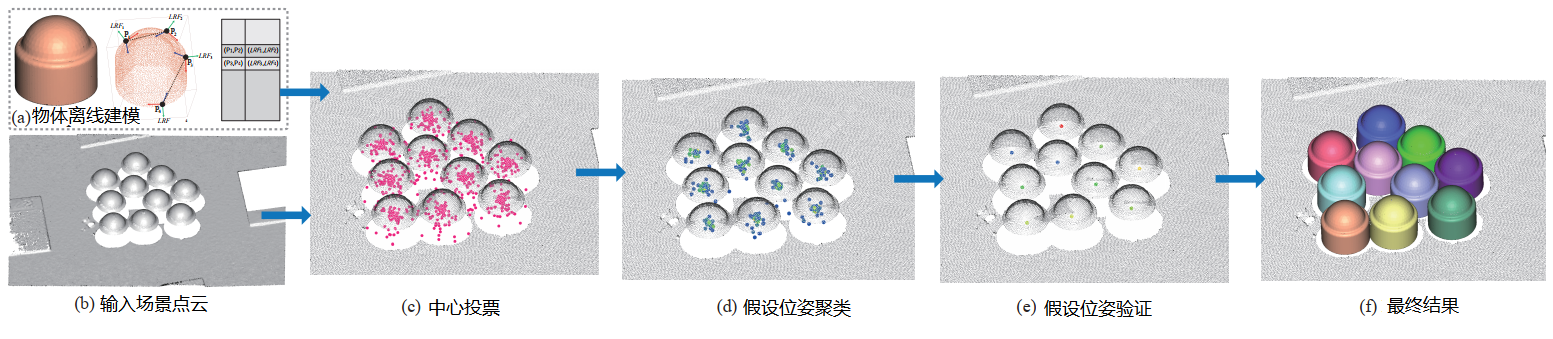
图2 技术路线图
5.1 点云预处理
通常,原始三维物体和场景点云规模大、密度高,若直接进行匹配估计位姿,计算效率低,难以满足应用需求,需要对原始点云进行下采样处理。传统的下采样方法有基于体素网格均匀采样和随机采样,这两种方法不考虑物体或场景表面形状特征信息,当体素分辨率较低或随机采样点云规模较小时,会消除或扭曲物体表面的几何特征。为了解决这一缺陷,我们采用了一种的自适应下采样方法,该方法考虑了点云法向信息,利用点之间法向夹角大小反应物体表面几何特征变化。我们首先创建一个从细到粗的多层体素网格;然后从细到粗逐层在每个体素中对相似点进行合并。通过该方法可以将物体或场景表面上几何形状特征(如边缘或曲率大的表面)变化剧烈的部分采样更多的点,而平面部分采样点较稀疏。
5.2 物体离线建模
在离线阶段,首先对输入目标对象点云进行下采样,生成一个稀疏采样点集。然后由稀疏采样点集组成的点对特征建立特征哈希表描述模型。具体来说,先计算目标采样点每组点对的PPF向量值,分别用距离离散尺度![]() 和角度离散尺度
和角度离散尺度![]() 离散PPF向量值的距离和角度元素,再将离散特征向量将点对散列到哈希表中。同时,我们还记录了目标对象包围盒中心和2个顶点组成的一个特征点集
离散PPF向量值的距离和角度元素,再将离散特征向量将点对散列到哈希表中。同时,我们还记录了目标对象包围盒中心和2个顶点组成的一个特征点集![]() ,另外为了减少在线匹配过程中的重复计算,还需要记录模型表面参考点
,另外为了减少在线匹配过程中的重复计算,还需要记录模型表面参考点![]() 和目标点
和目标点![]() 的局部坐标系,他们的局部坐标系定义为:
的局部坐标系,他们的局部坐标系定义为:
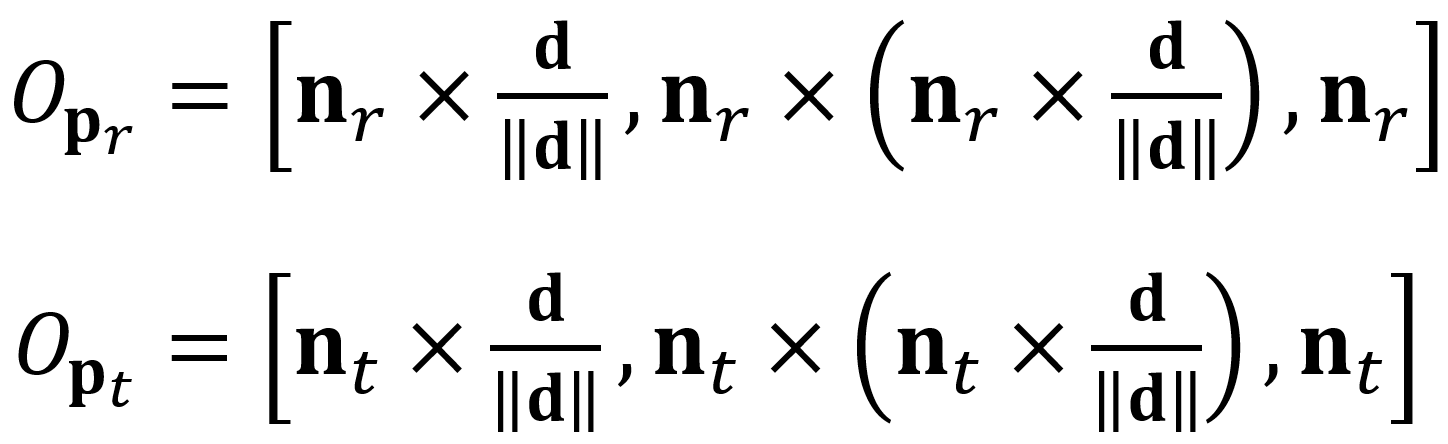
其中,操作符![]() 是向量之间的叉乘。
是向量之间的叉乘。
5.3 基于物体中心投票估计备选位姿
传统的PPF算法中,投票矩阵为目标对象参考点及其变换旋转角组成的二维表。由于受点云噪声及法向计算误差影响,该投票矩阵最大的投票位置经常不是正确位姿位置,需要将给定大于阈值所有投票位置确定的位姿计入备选位姿集合中;另一方面,由于经过下采样的目标对象点云和场景目标实例点云都是稀疏点云,对象和实例表面上相同位置的点云分布位置及法向信息也存在差异,增加了估计位姿的误差。本文利用匹配点对特征之间的几何关系备选位姿。实际应用中,可检测场景目标实例的可见表面至少有几个参考点,理论上这些参考点获得目标对象位姿是相似的,虽然传统方法通过后期聚类合并相似变换矩阵的投票数改善假设位姿的投票数,但这也会增加错误位姿投票数。本文中采用模型中心投票的方式获得每个场景目标实例的假设特征点集![]() ,通过对特征点集
,通过对特征点集![]() 聚类改善假特征点集的投票数,然后通过特征点集
聚类改善假特征点集的投票数,然后通过特征点集![]() 聚类中心估计位姿矩阵。这样做的优点是点集聚类量纲是统一的,只需要一个超参数,而变换矩阵聚类需要两个超参数,减少超参数规模降低了聚类难度;而且最终位姿通过目标对象的特征点集
聚类中心估计位姿矩阵。这样做的优点是点集聚类量纲是统一的,只需要一个超参数,而变换矩阵聚类需要两个超参数,减少超参数规模降低了聚类难度;而且最终位姿通过目标对象的特征点集![]() 与场景目标实例特征点集
与场景目标实例特征点集![]() 聚类中心估计,包含了多个场景参考点的信息。
聚类中心估计,包含了多个场景参考点的信息。
5.4 假设位姿验证
虽然中心投票估计目标对象位姿比传统PPF投票方法有更好的鲁棒性,但是也不能满足最高投票的位姿就是最优匹配位姿条件,并且在多实例场景中,如果我们只是按照评分顺序选取前k个最高得分的位姿,这些位姿之间可能有重叠,出现错误或丢失的匹配。因此需要进一步验证假设位姿验证。我们验证指标是变换后模型与场景之间的重合度。如果变换后模型点![]() 与场景点
与场景点![]() 满足条件:
满足条件:![]() 和
和 ![]() 其中
其中 ![]() 是一个距离阈值,
是一个距离阈值,![]() 是一个角度阈值,则认为变换后模型点
是一个角度阈值,则认为变换后模型点![]() 与场景是重合的。重合度定义为变换后模型点云中与场景重合点数量与模型所有点数量的比值。为了重新评估验证位姿重合度得分,首先根据备选位姿将模型转换到场景中,计算变换模型与场景的重合度,重叠度最高的位姿是最佳匹配位姿。在场景中有多个目标实例的情况下,我们使用非最大值抑制算法来过滤错误位姿,从而获得多个目标实例位姿。
与场景是重合的。重合度定义为变换后模型点云中与场景重合点数量与模型所有点数量的比值。为了重新评估验证位姿重合度得分,首先根据备选位姿将模型转换到场景中,计算变换模型与场景的重合度,重叠度最高的位姿是最佳匹配位姿。在场景中有多个目标实例的情况下,我们使用非最大值抑制算法来过滤错误位姿,从而获得多个目标实例位姿。
- 实验结果
本文在UWA、Toshiba CAD和DTU数据集上做了对比试验,并取得了最优性能。
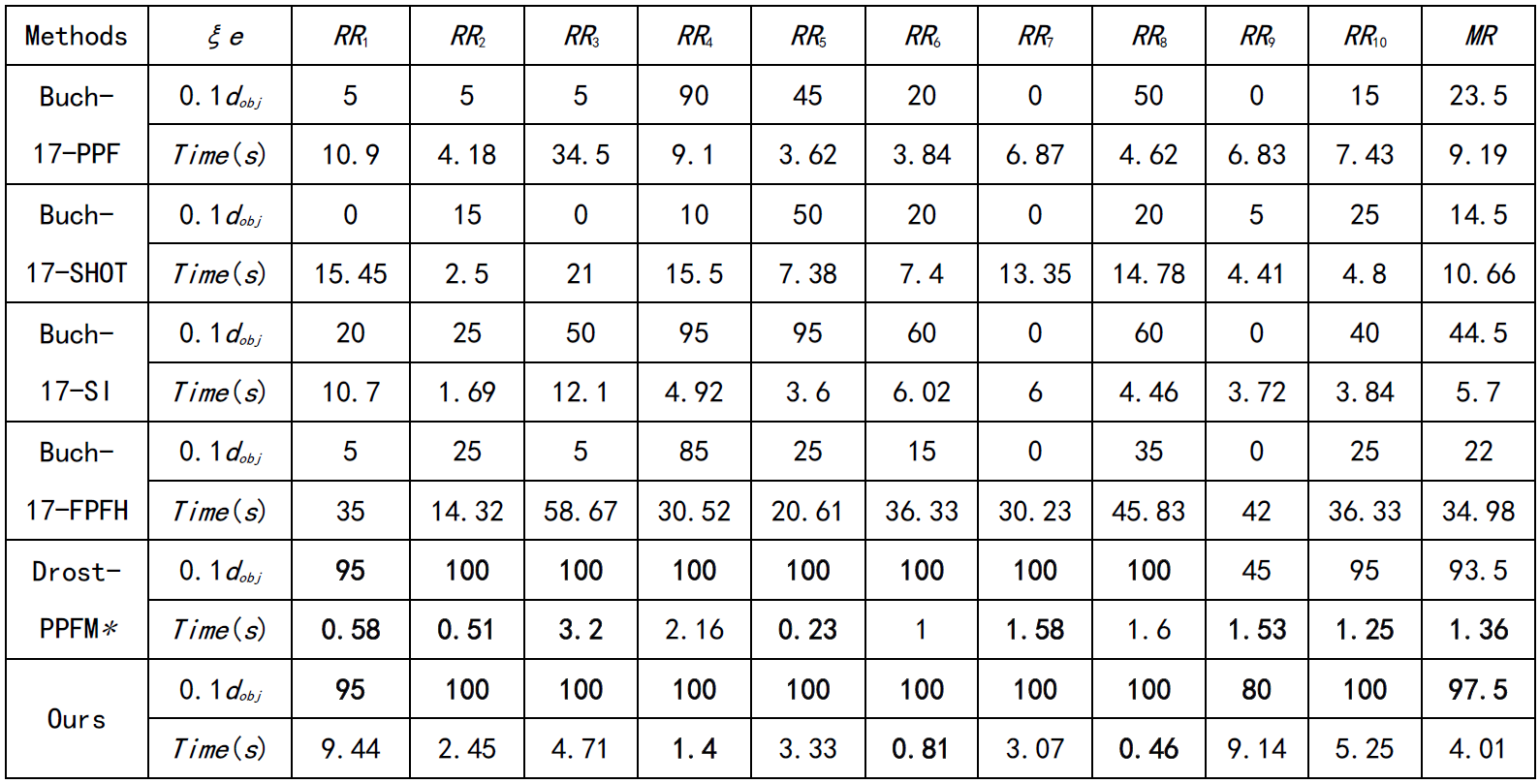
表1 Toshiba CAD数据集上的定量比较
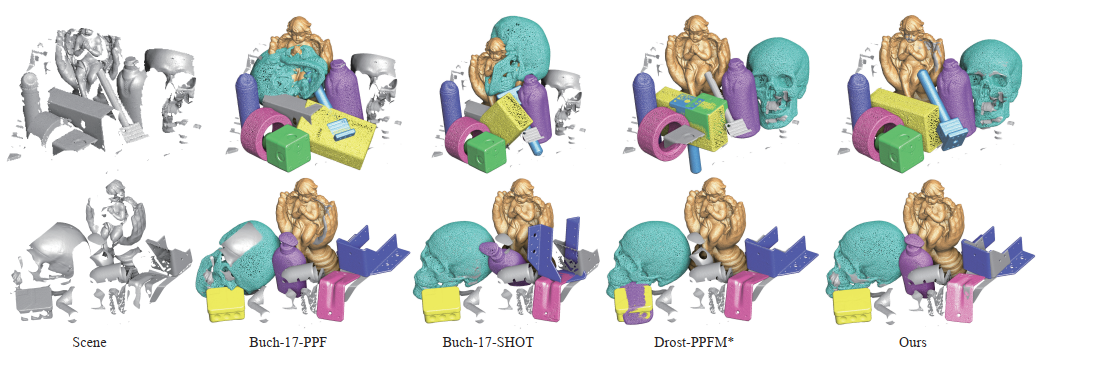
图3 DTU 数据集上的定性比较
另外,我们在实际点云数据上进行了测试,验证了我们方法的有效性,如图4所示。


图4 在实际点云数据上的检测结果
- 参考文献
- [1] Drost B, Ulrich M, Navab N, et al. Model globally, match locally: Efficient and robust 3D object recognition[C]//2010 IEEE computer society conference on computer vision and pattern recognition. Ieee, 2010: 998-1005.
- [2] Mian A S, Bennamoun M, Owens R. Three-dimensional model-based object recognition and segmentation in cluttered scenes[J]. IEEE transactions on pattern analysis and machine intelligence, 2006, 28(10): 1584-1601.
- [3] Pham M T, Woodford O J, Perbet F, et al. A new distance for scale-invariant 3D shape recognition and registration[C]//2011 International Conference on Computer Vision. IEEE, 2011: 145-152.
- [4] Sølund T, Buch A G, Krüger N, et al. A large-scale 3D object recognition dataset[C]//2016 Fourth International Conference on 3D Vision (3DV). IEEE, 2016: 73-82.