
1.论文动机
由单张人体图像来生成任意视角任意姿态下的图像,是近几年视觉领域研究的热点问题。现有方法无法实现灵活的图像编辑且难以合理预测不可见信息,其根本原因是衣服形状与风格/纹理的耦合以及空域相关信息的丢失。为了解决以上问题,该研究工作设计了形状与风格/纹理信息的分离方案,建立了分阶段分区域图像表示模型,联合局部与全局信息对目标图像进行合理预测,同时使用空间感知的正则化方法保留空间信息,实现了语义引导的新姿态图像生成与编辑,突破了形状与纹理难以解耦的瓶颈,并赋予算法灵活可控的编辑能力。
2.论文题目
[CVPR 2021] PISE: Person Image Synthesis and Editing with Decoupled GAN
张劲松(天津大学),李坤(天津大学),来煜坤(卡迪夫大学),杨敬钰(天津大学)
论文链接:http://cic.tju.edu.cn/faculty/likun/projects/PISE
代码开源: https://github.com/Zhangjinso/PISE
3.创新点
该方法使用分阶段分区域模型对人体图像合成过程中的形状和纹理信息进行解耦,实验结果展示了该方法在人体姿态迁移方面的优越性能以及对人体图像编辑的灵活性。
在目标图像生成的过程中,该方法结合局部和全局语义区域的特征,基于正则化方法对原始图像不同区域的纹理特征进行迁移及预测。
该方法使用空间感知的正则化方法对原图像中的空间信息进行变换,从而保留原始图像中的空间信息。
4.相关工作
以往方法[1-4]针对如何提升人体姿态迁移系统的性能,即对如何生成更真实的图片进行了大量的研究。然而,人体姿态迁移系统生成人体图像的整个过程是不可控的,只能迁移姿态,不能迁移衣服的形状或者衣服的纹理。PINet[5]和ADGAN[6]对人体姿态迁移的可控性能进行了探索,但难以细致地控制属性,只能大致调整生成人物图像的穿着,不能灵活地控制其衣物样式及纹理。
5.方法描述
该工作的目标是在实现人体姿态迁移,即分离出人体姿态的基础上,解耦形状信息与纹理信息,从而实现灵活的人体图像编辑。然而将形状信息与纹理信息从耦合的图像中分离出来是非常困难的。为此,作者引入人体语义分割图作为中间结果,将形状信息显示地表示出来。具体来说,该方法分为两个阶段:1)采用解析生成器(Parsing Generator)根据原始语义分割图与目标姿态,生成目标图像的语义分割图;2)采用图像生成器(Image Generator)将生成的语义分割图依据输入图像转换为目标图像。
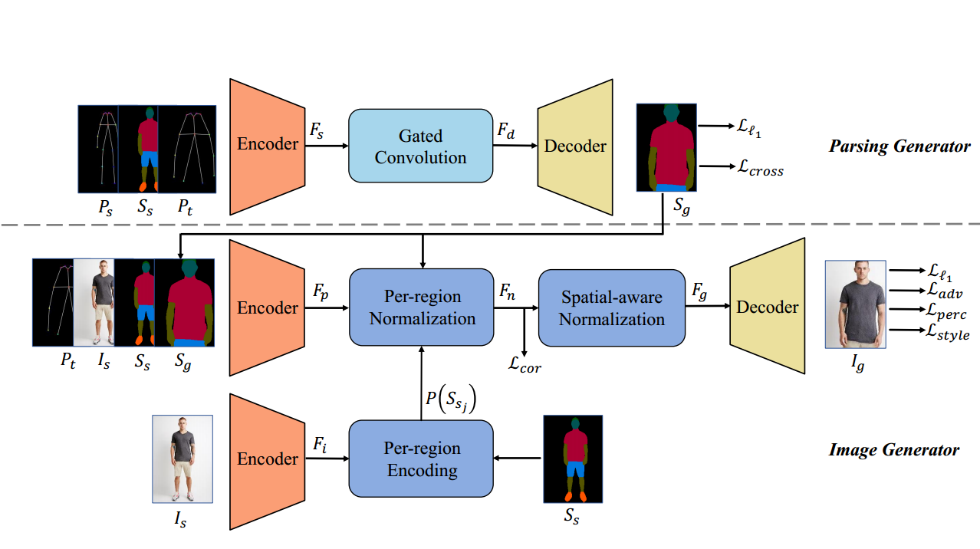
Parsing Generator
首先,作者使用OpenPose[7]提取出的18个关键点表示人体姿态信息,使用CIHP PGN[8]得到原始图像的人体语义分割图。Parsing Generator负责根据目标姿态、原始姿态及其语义分割图去生成目标人物的语义分割图。相比于直接对像素点的RGB进行预测输出最终结果的方法,两阶段的结构在一定程度上降低了问题的难度。但对目标人物的语义分割图进行预测仍然是一个输入输出不对齐的问题。传统卷积对输入特征不同空间位置信息是平等对待的,因此并不适用于需要对特征进行空间变换的问题。作者在特征空间采用了门控卷积(gated convolution)来动态地赋予空间注意力,将原始姿态下的语义图变换为目标姿态下的语义图。
Image Generator
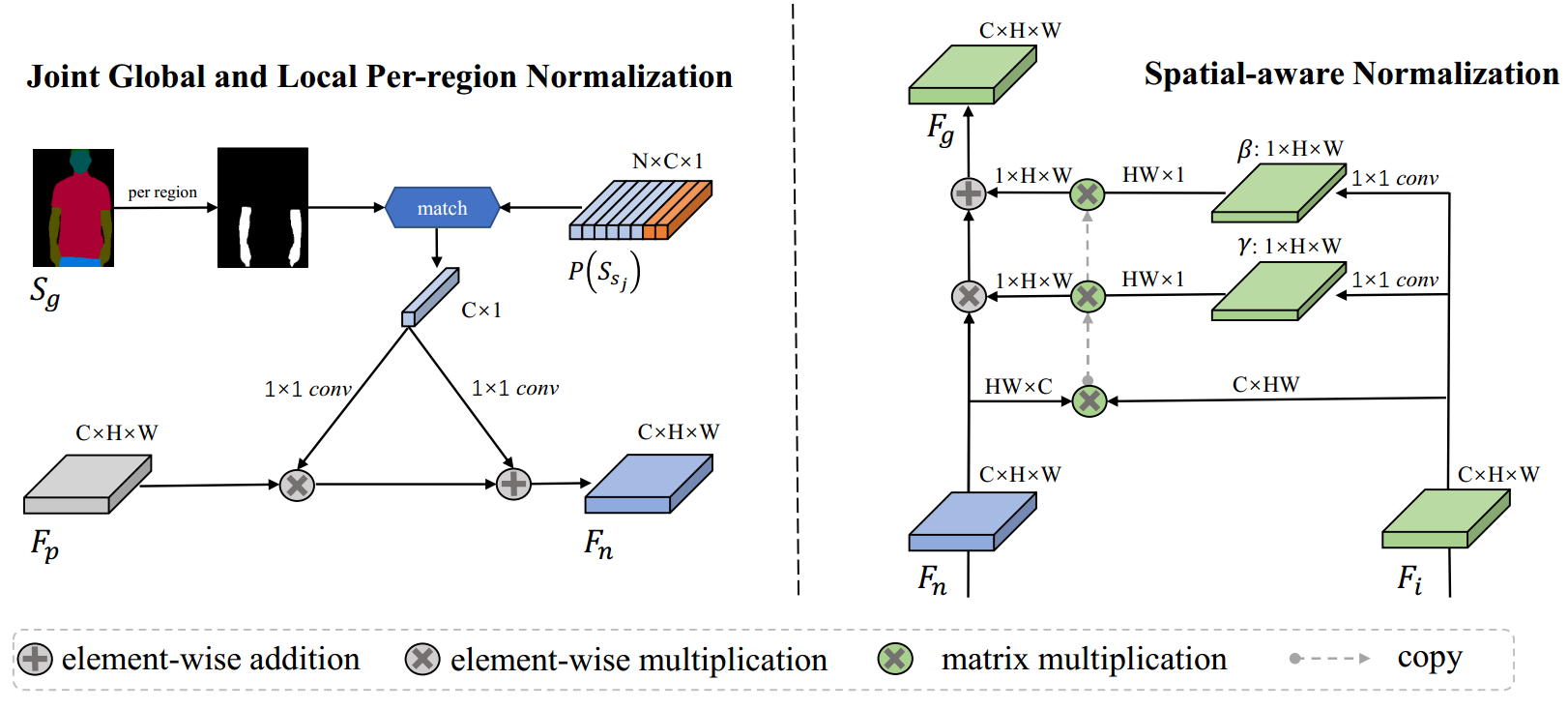
通过将人体语义分割图作为中间结果,作者把形状信息显示地表示了出来。基于此,作者进一步将解耦形状信息与纹理信息转化为解耦每个语义区域的形状信息与纹理信息。首先,提取原始图像的特征,并根据原始图像的语义图,针对每个语义区域提取和形状无关的特征向量。在根据第一阶段产生的目标语义图生成目标图像的过程中,对于在原图像中可见的区域,使用原图像对应语义区域的特征向量进行调制;对于在原图像中不可见的区域,使用原图像所有区域的特征向量对其进行预测。之后,将原图像中与形状无关的纹理信息使用正则化的方式注入到生成的图像特征中。然而,在提取原图像不同语义区域特征的过程中,丢失了每个语义区域的空间信息。为了保留原图像中每个语义区域的空间信息,作者引入了空间感知的归一化方法。在对生成特征注入纹理信息时,使用目标图像的VGG特征进行约束,使两者尽可能处于同一域内,进而计算两者的注意力图。之后,对原图像特征进行通道归一化,保留其空间信息,使用之前预测的注意力图对原始图像的空间特征进行变形,进而得到与目标图像对齐的空间特征,并使用正则化方式进行特征调制。整个过程在尽可能保持原图像中的纹理信息与空间信息的基础上,通过全局与局部联合的分区域归一化以及空间感知归一化方法,解耦了形状信息与纹理信息。
6.实验结果
在人体姿态迁移任务上,作者在DeepFashion数据集上与六种SOTA方法进行了对比。在定性比较上,该方法获得了最好的视觉结果,同时和原图像中的人物和衣着有着更高的一致性,空间上下文信息也很好地保留了下来。

在定量比较上,该方法产生的结果误差最小,有着最好的真实性以及与目标图像的一致性。
此外,作者还进行了纹理迁移和语义图编辑的实验,证明了该方法可以对人物图像进行灵活可控的编辑。更多的结果请参见该工作的论文与补充材料。


7.参考文献
[1] Zhen Zhu, Tengteng Huang, Baoguang Shi, Miao Yu, Bofei Wang, and Xiang Bai. Progressive pose attention transfer for person image generation. In Proc. IEEE Conf. Comput. Vis. Pattern Recog., pages 2342–2351, 2019.
[2] Kun Li, Jinsong Zhang, Yebin Liu, Yu-Kun Lai, Qionghai Dai. PoNA: Pose-guided Non-local Attention for Human Pose Transfer. IEEE Trans. Image Processing, vol. 29, pp. 9584-9599, 2020.
[3] Hao Tang, Song Bai, Philip HS Torr, and Nicu Sebe. Bipartite graph reasoning gans for person image generation. In Proc. Brit. Mach. Vis. Conf., 2020. 1, 6, 7
[4] Hao Tang, Song Bai, Li Zhang, Philip HS Torr, and Nicu Sebe. Xinggan for person image generation. In Proc. Eur. Conf. Comput. Vis., 2020.
[5] Jinsong Zhang,Xingzi Liu,Kun Li. Human Pose Transfer by Adaptive Hierarchical Deformation. Computer Graphics Forum, vol. 39, no. 7, pp. 325-337, 2020.
[6] Yifang Men, Yiming Mao, Yuning Jiang, Wei-Ying Ma, and Zhouhui Lian. Controllable person image synthesis with attribute-decomposed gan. In Proc. IEEE Conf. Comput. Vis. Pattern Recog., pages 5083–5092, 2020.
[7] Zhe Cao, Tomas Simon, Shih-En Wei, and Yaser Sheikh. Realtime multi-person 2D pose estimation using part affinity fields. In Proc. IEEE Conf. Comput. Vis. Pattern Recog., 2017.
[8] Ke Gong, Xiaodan Liang, Yicheng Li, Yimin Chen, Ming Yang, and Liang Lin. Instance-level human parsing via part grouping network. In Proc. Eur. Conf. Comput. Vis., 2018.