
- 导读
在CVPR 2021上,浙江大学CAD&CG国家重点实验室、浙大-商汤三维视觉联合实验室提出了一种新颖的局部图像特征匹配方法。LoFTR利用自注意力和交叉注意力机制直接在低分辨率的特征图上建立逐特征的粗粒度匹配,然后在高分辨率特征图上进行优化求得亚像素级别的精确匹配。相比较于传统方法,LoFTR使用Transformer构建了基于两张图、具有全局感知野的特征,能够在弱纹理区域构建精准的匹配。LoFTR在室内、室外数据集和视觉定位公开排行榜上均取得了领先地位。
- 论文题目
[CVPR 2021] LoFTR: Detector-Free Local Feature Matching with Transformers
Jiaming Sun(Zhejiang University, SenseTime Research), Zehong Shen(Zhejiang University), Yuang Wang(Zhejiang University), Hujun Bao(Zhejiang University), Xiaowei Zhou(Zhejiang University)
论文链接:https://arxiv.org/pdf/2104.00680
代码开源: https://github.com/zju3dv/LoFTR
- 问题和挑战
图像特征匹配任务是三维计算机视觉的基本任务,在SfM、SLAM、视觉定位等应用中在机器人、增强现实等场景有着广泛的应用。例如通过稀疏匹配求解相机相对位姿,通过稠密匹配还原场景的三维表达。以及增强混合现实中具有重要的意义。
当传感器之间的视角变化较大、纹理稀疏时,传统手工设计的图像特征描述子的多视角不变性较弱,关键点检测在多视角时可重复性下降、检测误差较大,难以形成精准的匹配。如下图SuperGlue方法,在纹理稀疏、纹理重复的墙和地板上难以建立足够多的正确匹配。其中的重要原因是关键点检测器难以找到高重复性的特征点,同时特征描述子难以同时兼具不变性与显著性。

- 方法描述
针对以上挑战,我们提出了一个新颖的特征匹配方法LoFTR,它是一种不依赖关键点检测的端到端特征匹配方案。LoFTR采用深度卷积神经网络与注意力机制得到基于两张图的特征描述子,并在此基础上形成粗粒度匹配,再逐步优化到细粒度,最终形成鲁棒且精确的半稠密图像匹配。
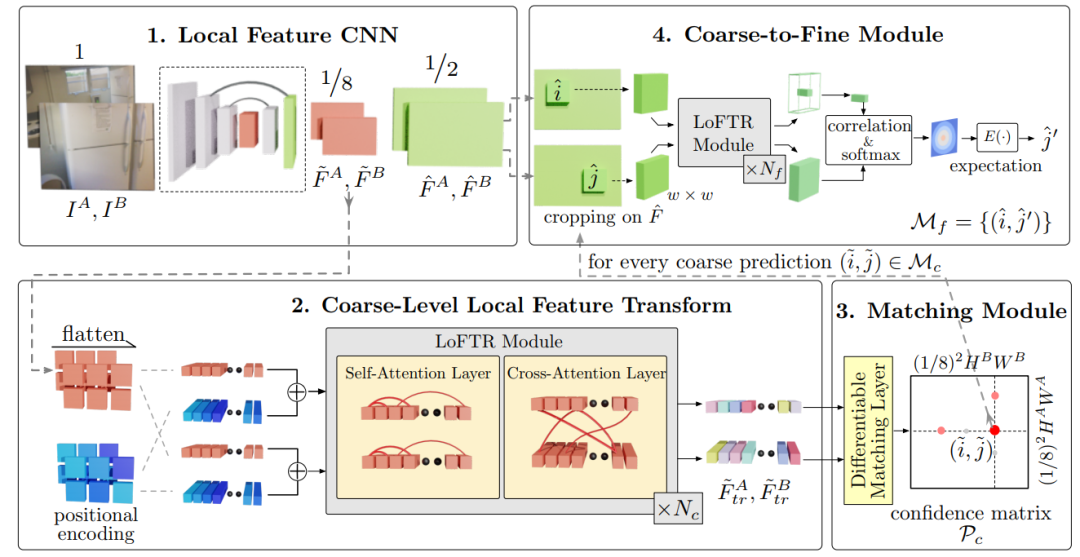
LoFTR的流程包括(1)通过一个卷积神经网络提取高低两种分辨率的特征图。(2)将低分辨率特征图展平并添加位置编码,然后由LoFTR模块,通过自注意与交叉注意让局部特征融合自身与对方的全局特征。(3)进行特征的可微分匹配得到置信度矩阵,根据阈值和相互最近邻标准得到最终匹配项。(4)对于每个挑选出的预测,在高分辨率特征图中挑选出窗口大小为w的对应特征。同样使用LoFTR模块进行特征的处理,然后通过求期望的方式达到最终的亚像素级别匹配。
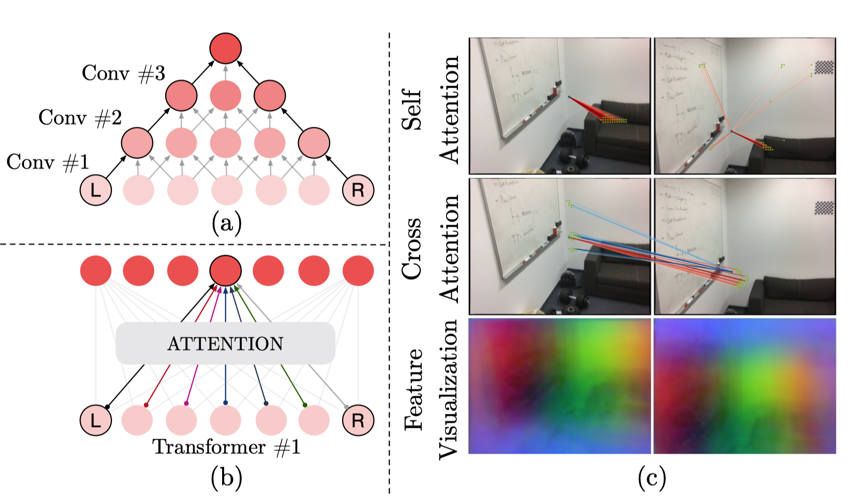
Transformers的作用:上图对比了卷积神经网络的感知野和注意力机制的感知野。对于L和R元素,卷积网络需要堆叠多层建立L和R的信息连接。而注意力机制的全局感知野只需要一层网络。上图还提供了自注意力与交叉注意力的可视化与LoFTR得到特征的PCA可视化。通过全局感知野和位置编码等设计,LoFTR在弱纹理区域也能学习兼顾不变形和显著性的优秀特征表达。
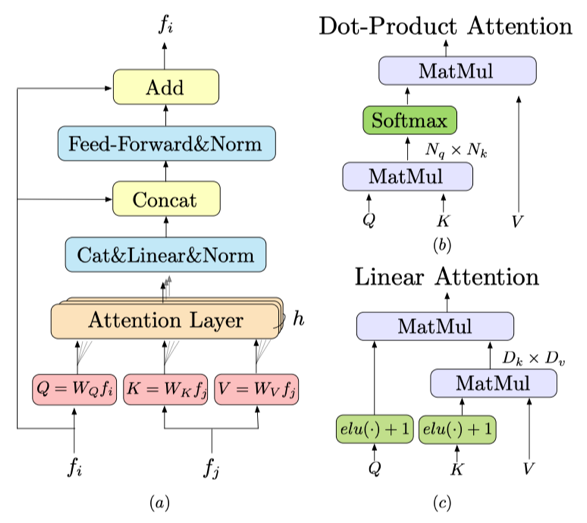
加速:经典的Transformer的注意力机制中,长度为N的query,key向量之间的点乘操作其复杂度是![]() ,对于图像匹配任务中,N与图像的像素总数成正相关。这对于大分辨率的图像将会是不切实际的。因此,我们引入了线性注意力机制[2],其大致思想是通过核方法将sim(Q,K)拆为
,对于图像匹配任务中,N与图像的像素总数成正相关。这对于大分辨率的图像将会是不切实际的。因此,我们引入了线性注意力机制[2],其大致思想是通过核方法将sim(Q,K)拆为![]() ,先处理
,先处理![]() ,由于在我们的任务中特征维度D≪N,因此总的计算代价将会将为O(N)。
,由于在我们的任务中特征维度D≪N,因此总的计算代价将会将为O(N)。
可微匹配层:我们提供了两种可选的可微匹配层。(1)Dual-Softmax。对于一张图中的一个点,将考虑另一张图中所有的待匹配项。将这个过程双向化。(2)Sinkhorn。考虑所有可能匹配的整体代价最优化,是一种最优传输的线性迭代求解方法。
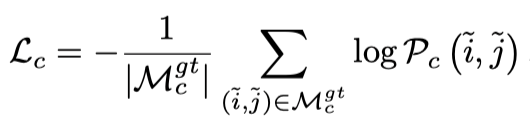
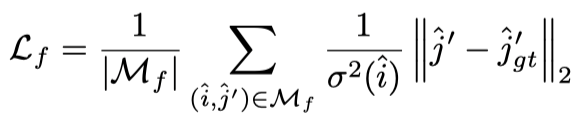
监督信号:(1)在粗粒度匹配层,我们对可微匹配层得到的稠密置信度矩阵使用NLL监督。即,对于能够建立ground-truth匹配的,给negative-log-likelihood监督。我们不需要对错误匹配监督,这是由于可谓匹配层保证了梯度能够有效回传给所有特征。(2)在细粒度匹配层,我们借鉴[3]对期望施加L2监督,同时使用方差赋予权重。
- 实验结果

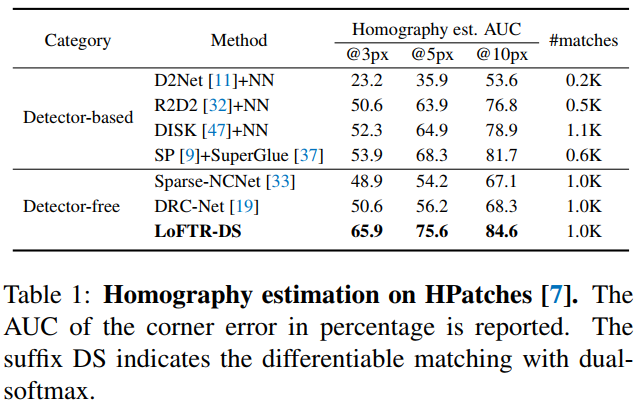
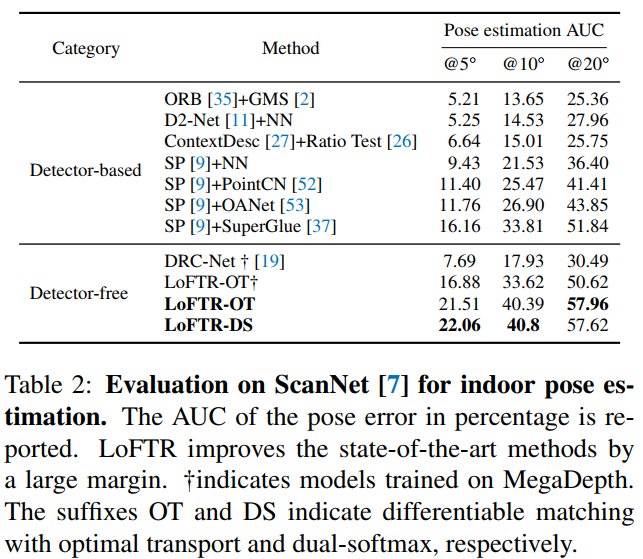

定量结果:我们通过计算重投影/相机相对位姿误差的AUC比较各种方法。LoFTR在Homography(HPatches)、室内(Scannet)和室外(Megadepth)数据集上均取得了第一的好成绩。显著超过了近些年提出的其他基于特征点的方法,如DISK、SuperPoint+SuperGlue等。
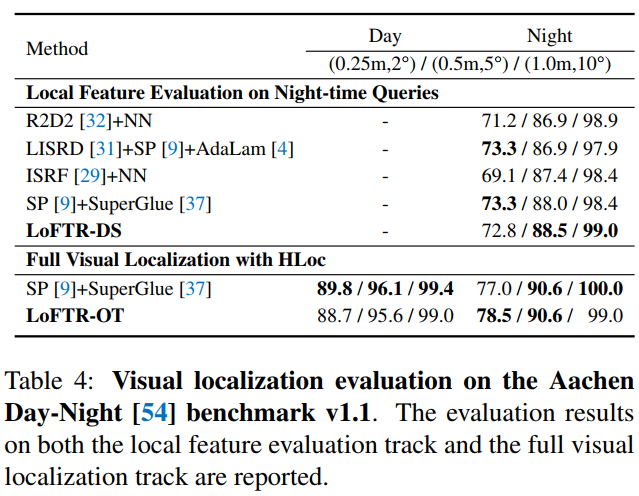
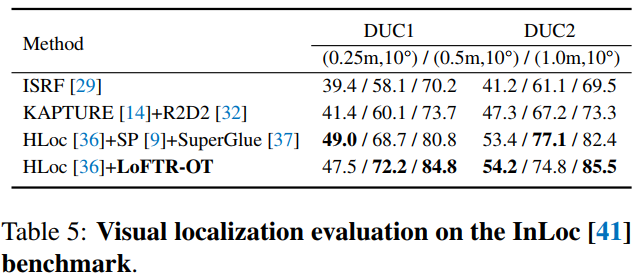
视觉定位:我们将我们的方法应用在视觉定位任务上,在排行榜(visuallocalization.net)上所有已发表方法中均排名第一(论文投稿时)。
弱纹理匹配效果:https://zju3dv.github.io/loftr/images/loftr-matches-compare.mp4
与SuperGlue比较:https://zju3dv.github.io/loftr/images/loftr_spg_compare.mp4
- 参考文献
- [1] Sarlin P E, DeTone D, Malisiewicz T, et al. Superglue: Learning feature matching with graph neural networks. In CVPR, 2020.
- [2] Angelos Katharopoulos, Apoorv Vyas, Nikolaos Pappas, and Franc¸ois Fleuret. Transformers are RNNs: Fast autoregressive transformers with linear attention. In ICML, 2020.
- [3] Qianqian Wang, Xiaowei Zhou, Bharath Hariharan, and Noah Snavely. Learning feature descriptors using camera pose supervision. In ECCV, 2020.